8.2.4 Podgląd i konfiguracja importu
8.2.4.1 Podgląd i konfiguracja importu danych z plików Excel
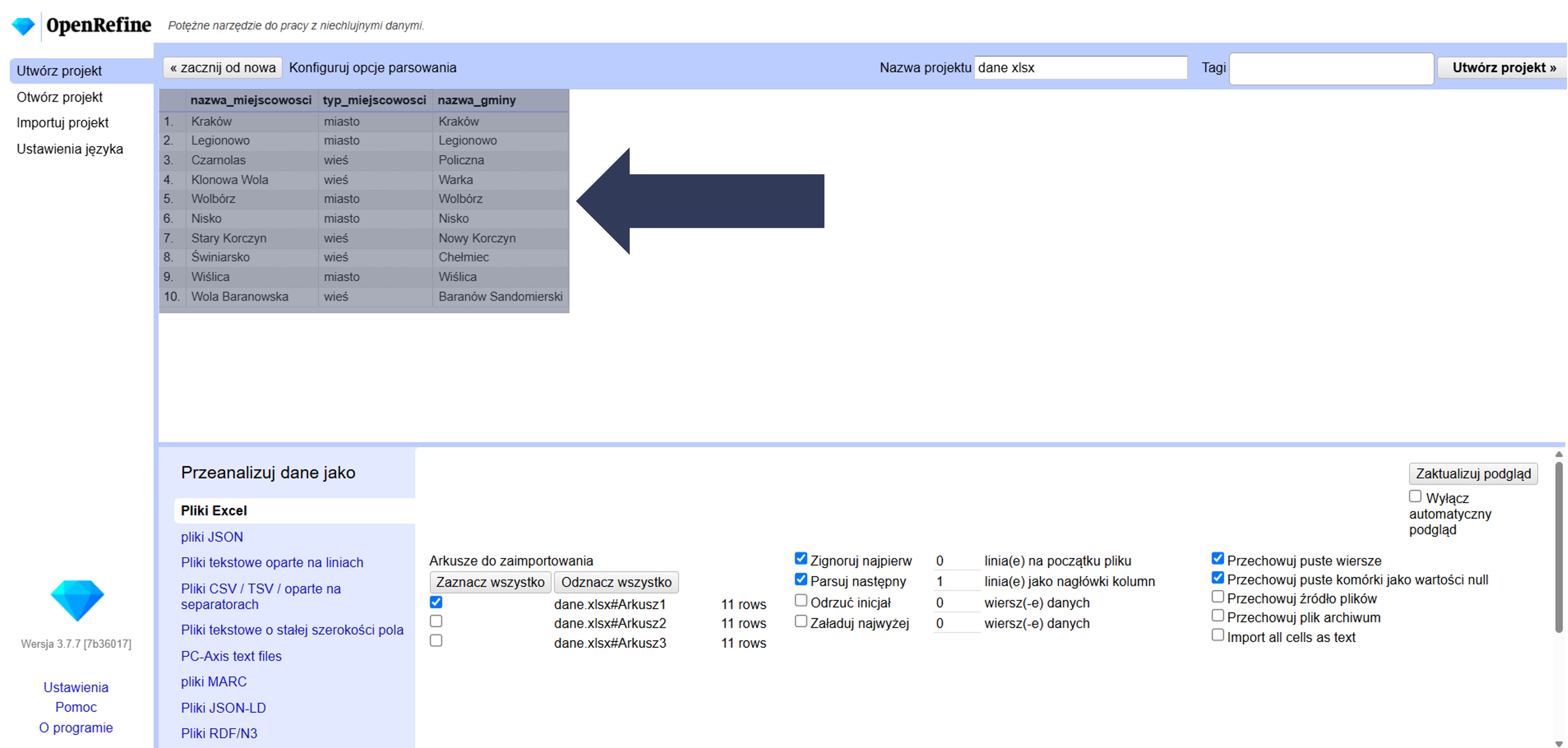
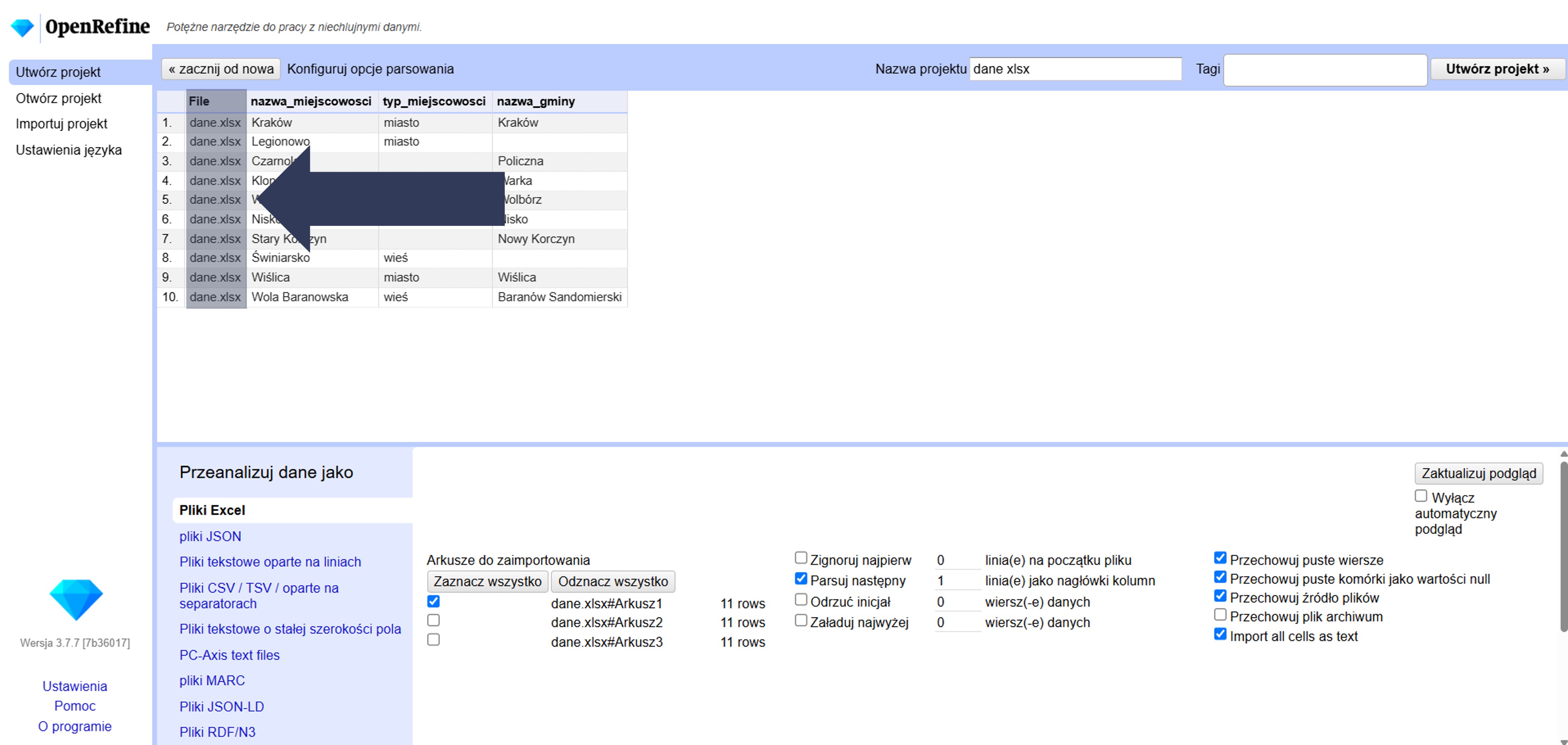
8.2.4.1.1 Wybór arkuszy do zaimportowania
Jeśli plik Excel ma wiele arkuszy, zaznacz te, które chcesz zaimportować. Domyślnie zaznaczony jest pierwszy arkusz.
Aby wybrać arkusze do zaimportowania:
- Odszukaj w sekcji Arkusze do zaimportowania listę arkuszy dostępnych w pliku.
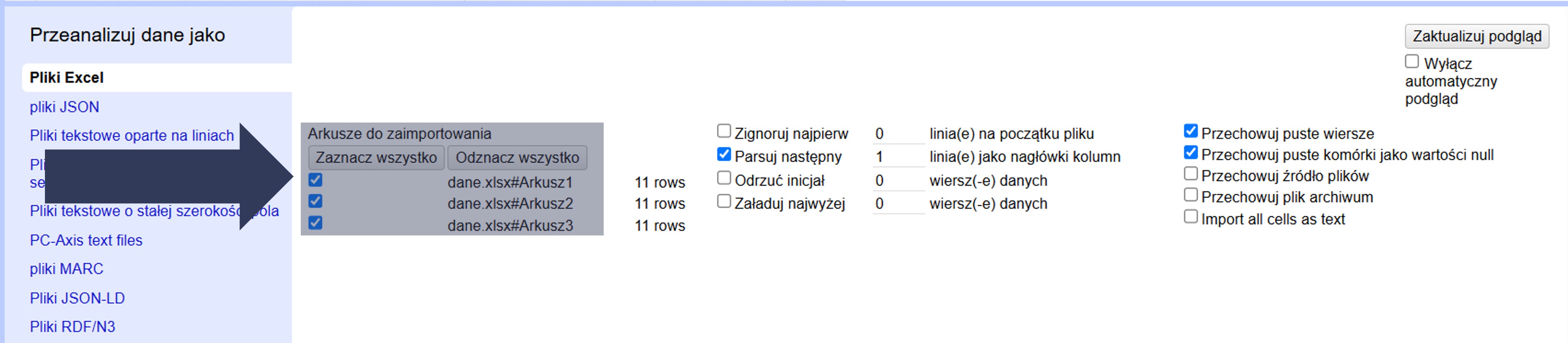
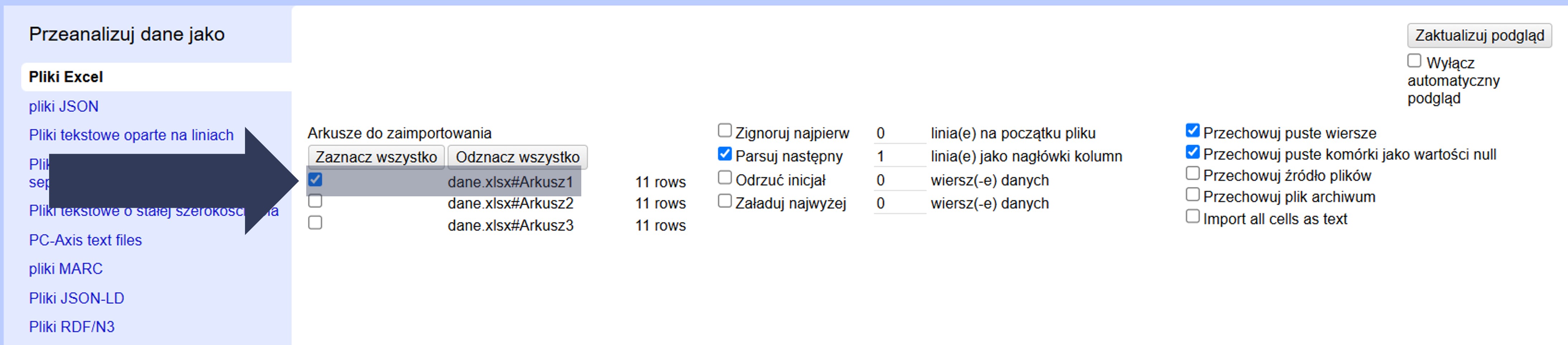
- Zaznacz pole wyboru przy nazwie arkusza (arkuszy), który chcesz zaimportować.
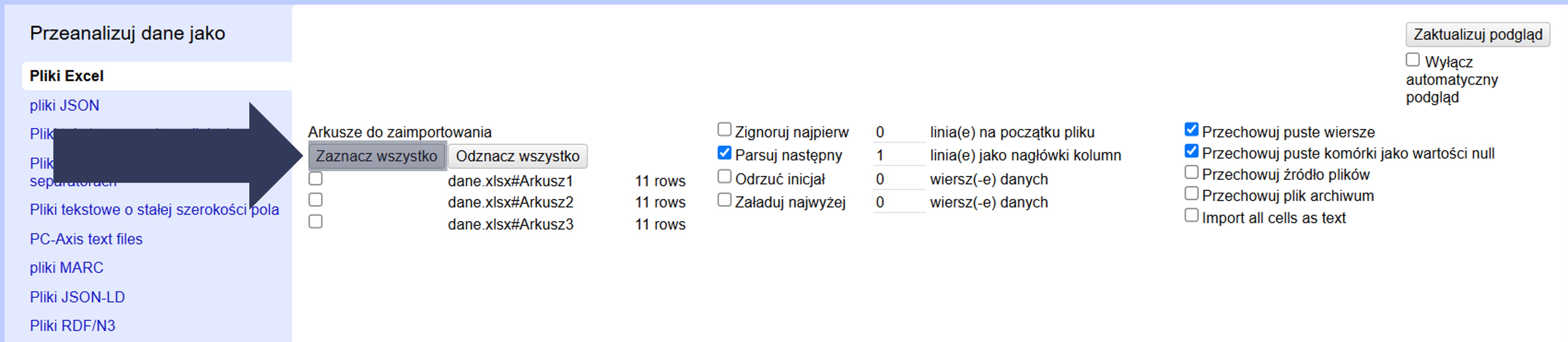
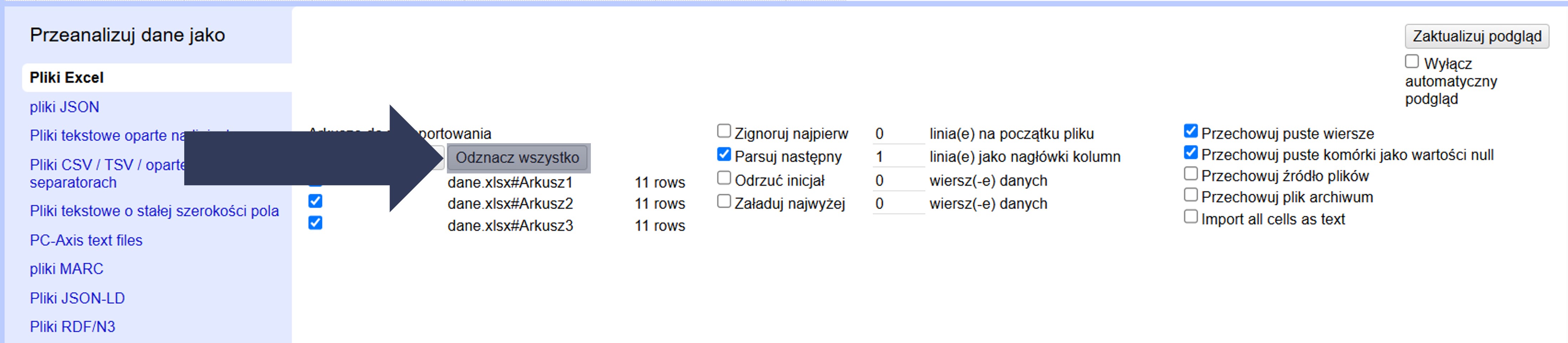
- Opcjonalnie: Kliknij Zaznacz wszystko, aby wczytać wszystkie arkusze, lub Odznacz wszystko, aby usunąć zaznaczenia i wybrać je ręcznie.
8.2.4.1.2 Ignorowanie początkowych linii arkusza danych
Jeśli na początku pliku znajdują się dodatkowe opisy, nagłówki techniczne, notatki lub inne metadane, możesz je pominąć, wskazując liczbę wierszy do odrzucenia.
Aby odrzucić z importu dane wiersze:
- W sekcji Opcje importu zaznacz pole Zignoruj najpierw … linia(e) na początku pliku.
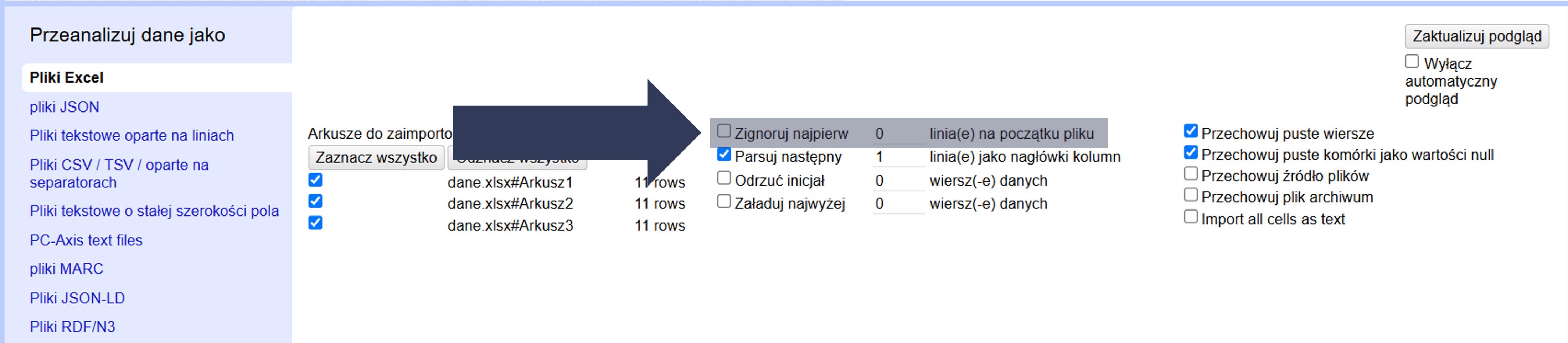
- Wpisz w polu liczbowym liczbę wierszy, które mają zostać pominięte.
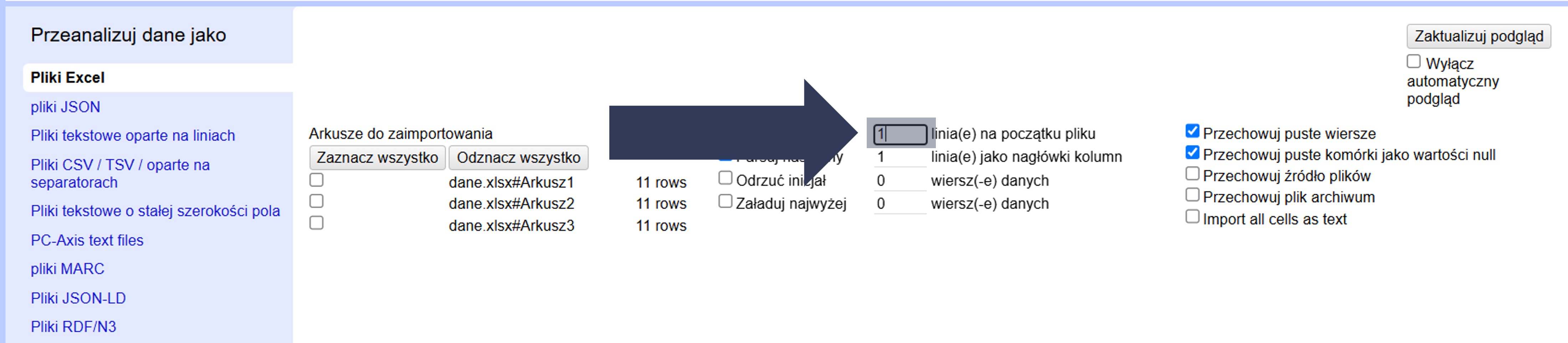
- Opcjonalnie: Pozostaw 0, aby wczytać wszystkie wiersze od początku.
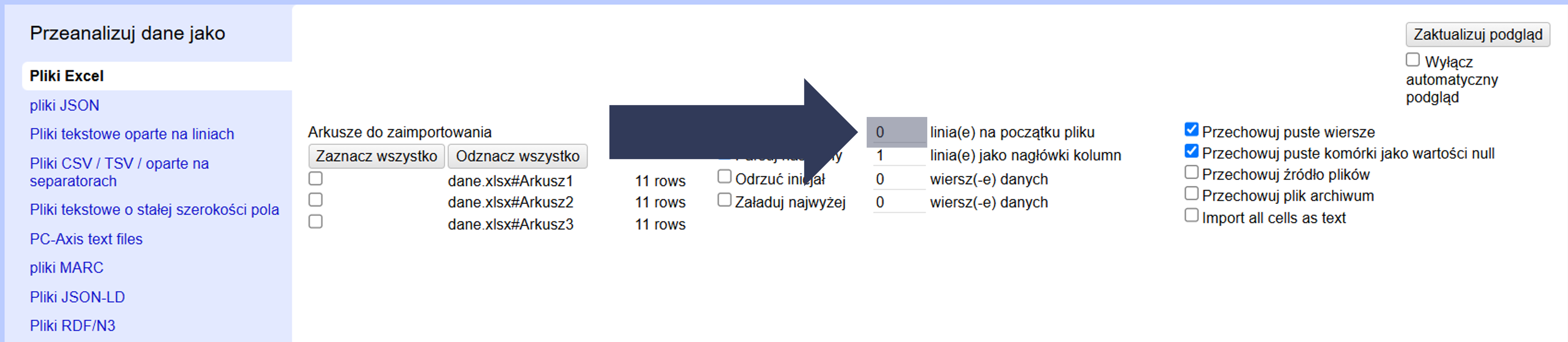
- Sprawdź w podglądzie danych, czy import rozpoczyna się od właściwego wiersza.
Wskazana liczba początkowych wierszy zostanie pominięta i nie trafi do projektu.
8.2.4.1.3 Ustawienia początkowych linii jako nazw kolumn
Jeśli pierwszy wiersz pliku zawiera nazwy kolumn, a dopiero od drugiego zaczynają się dane, zaznacz opcję Parsuj następny … jako nagłówki kolumn.
Aby ustawić pierwszy wiersz jako nagłówki kolumn:
- W sekcji Opcje importu zaznacz pole Parsuj następny … jako nagłówki kolumn.
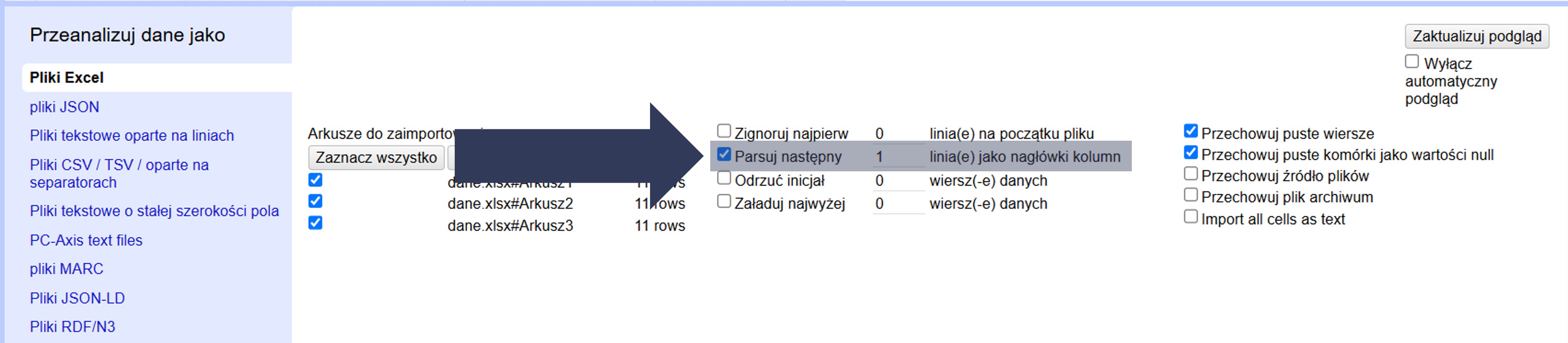
- W polu liczbowym obok pozostaw 1, jeśli nagłówki są w pierwszym wierszu danych.
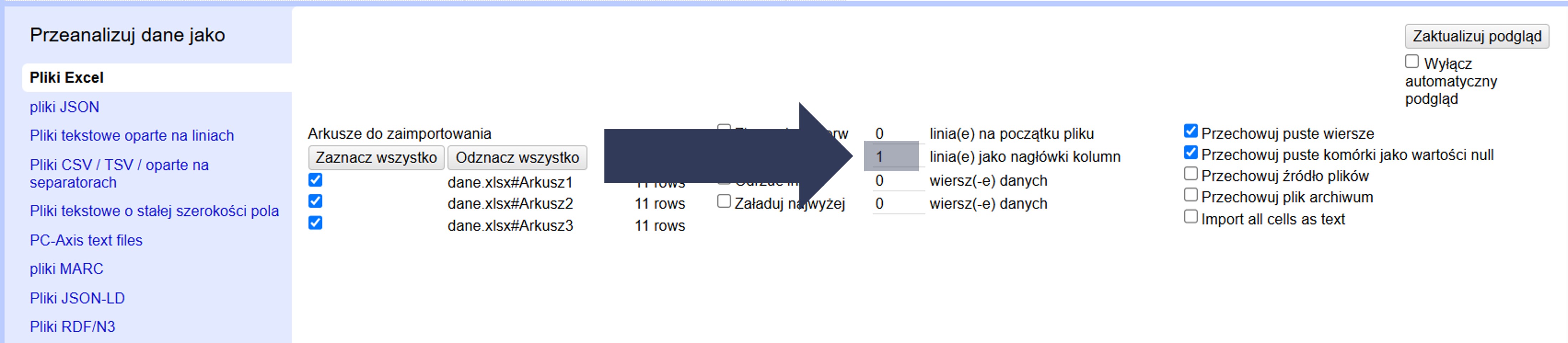
- Opcjonalnie: Wpisz inną wartość, jeśli nagłówki znajdują się dalej (np. 2, gdy pierwszy wiersz to notatka, a drugi zawiera nagłówki).
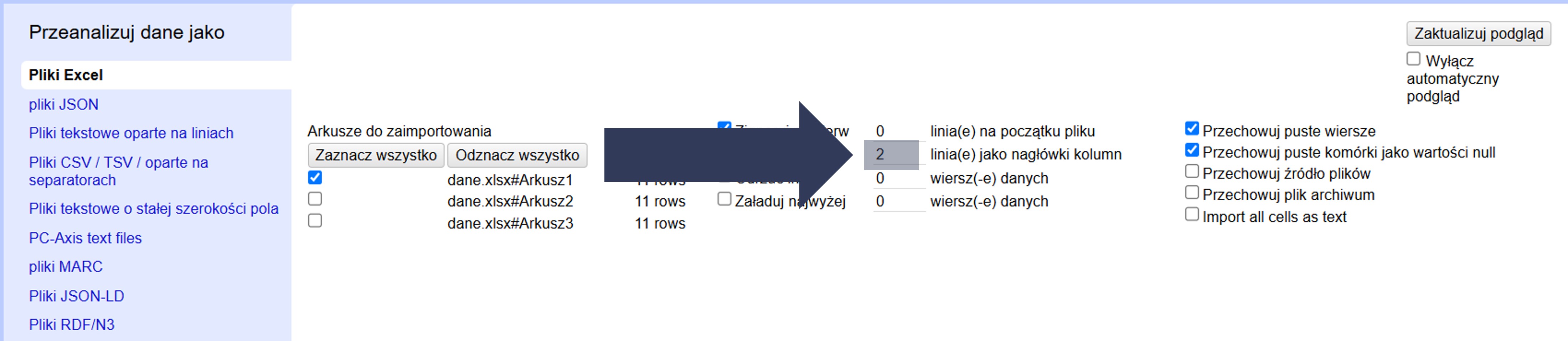
- Sprawdź w podglądzie danych (góra okna), czy kolumny mają poprawne nazwy.
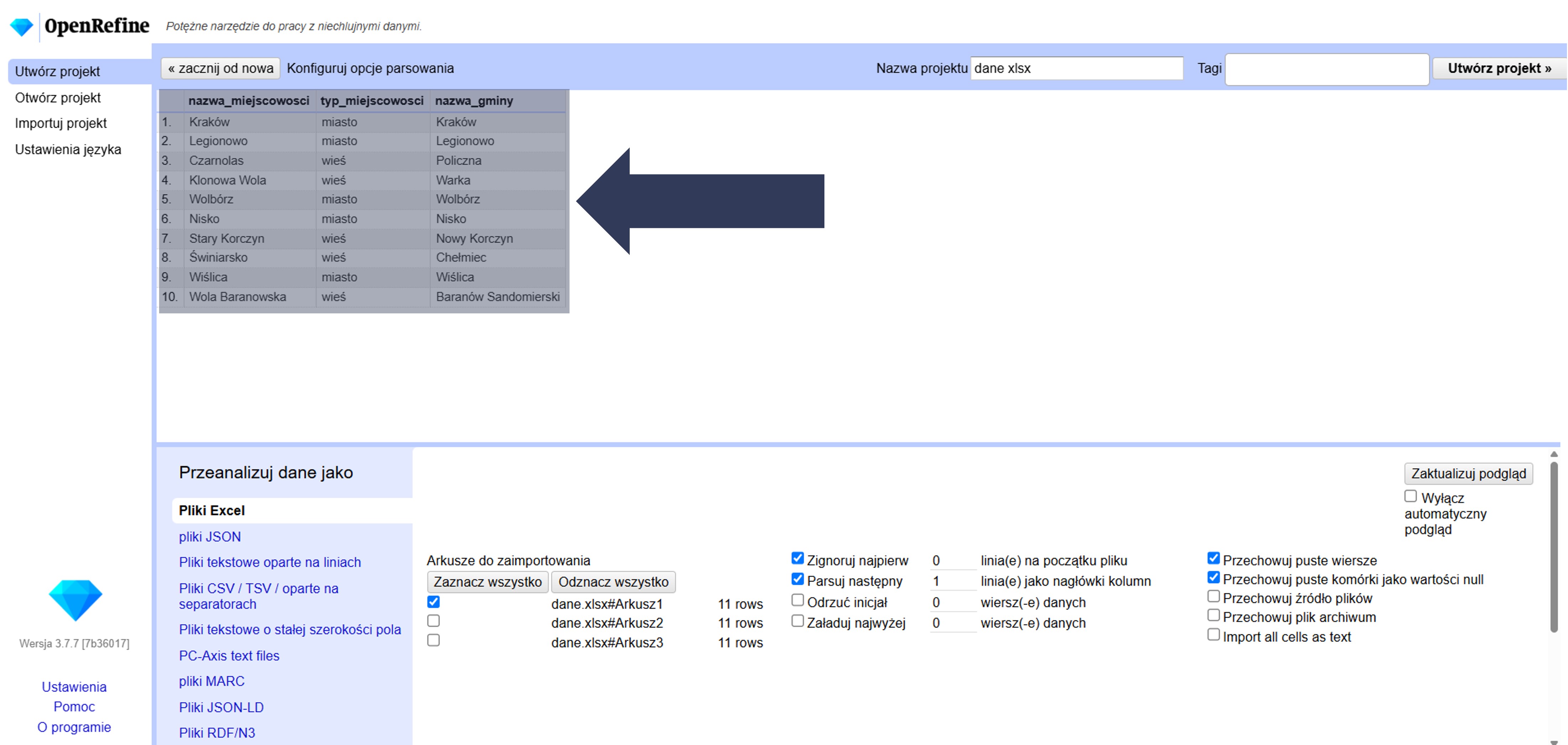
Wskazany wiersz zostanie użyty jako nagłówki kolumn, a sam wiersz nie trafi do danych.
8.2.4.1.4 Odrzucenie początkowych wierszy danych (nie nagłówków)
Opcja Odrzuć inicjał … wierszy danych pozwala pominąć pierwsze wiersze właściwych danych (nie dotyczy nagłówków). Stosuj w sytuacjach wyjątkowych, np. gdy początkowe rekordy są błędne, testowe lub nie powinny znaleźć się w projekcie.
Aby odrzucić początkowe wiersze danych z importu:
- W sekcji Opcje importu zaznacz pole Odrzuć inicjał … wierszy danych.
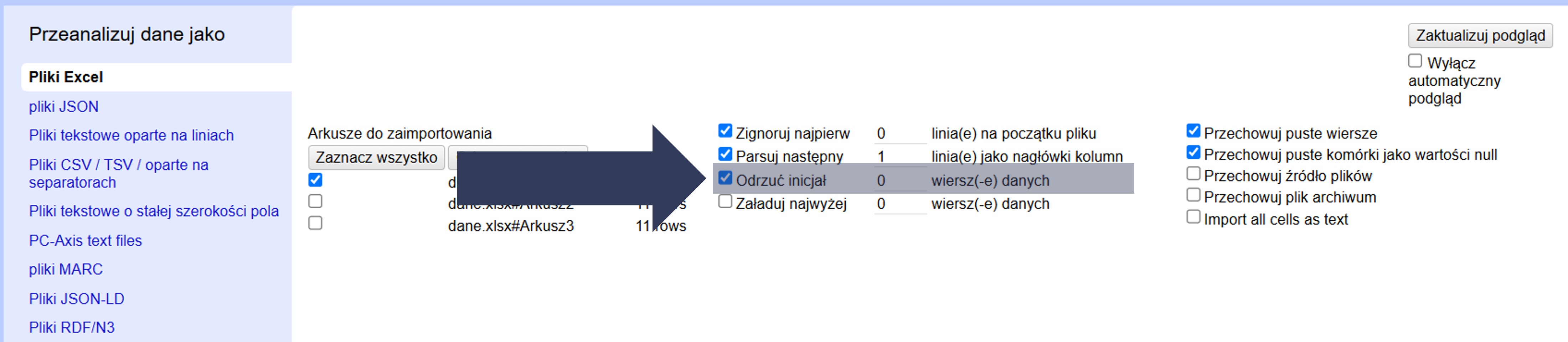
- Wpisz w polu liczbowym liczbę wierszy, które mają zostać pominięte.
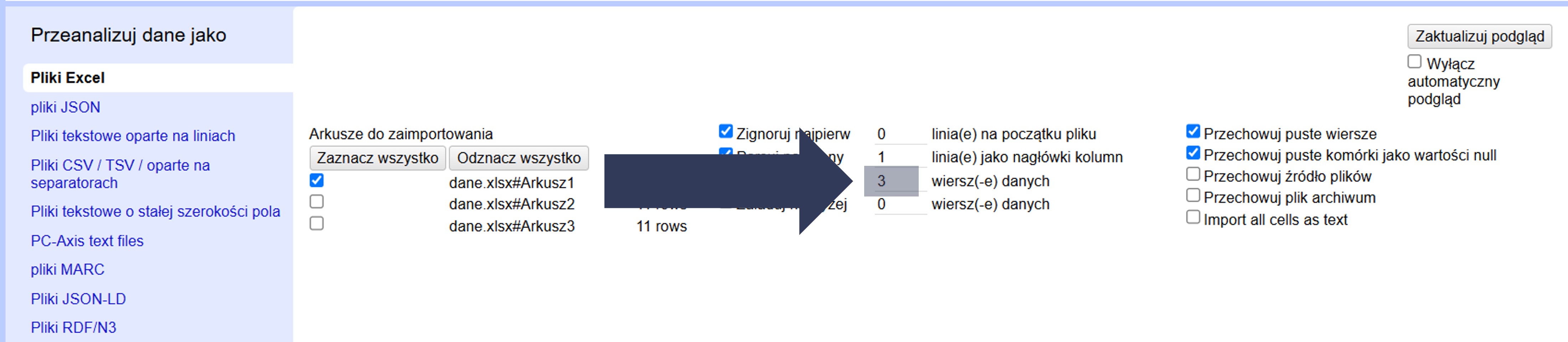
- Sprawdź w podglądzie danych (górna część okna), czy wiersze zostały odrzucone i import zaczyna się od właściwego miejsca.
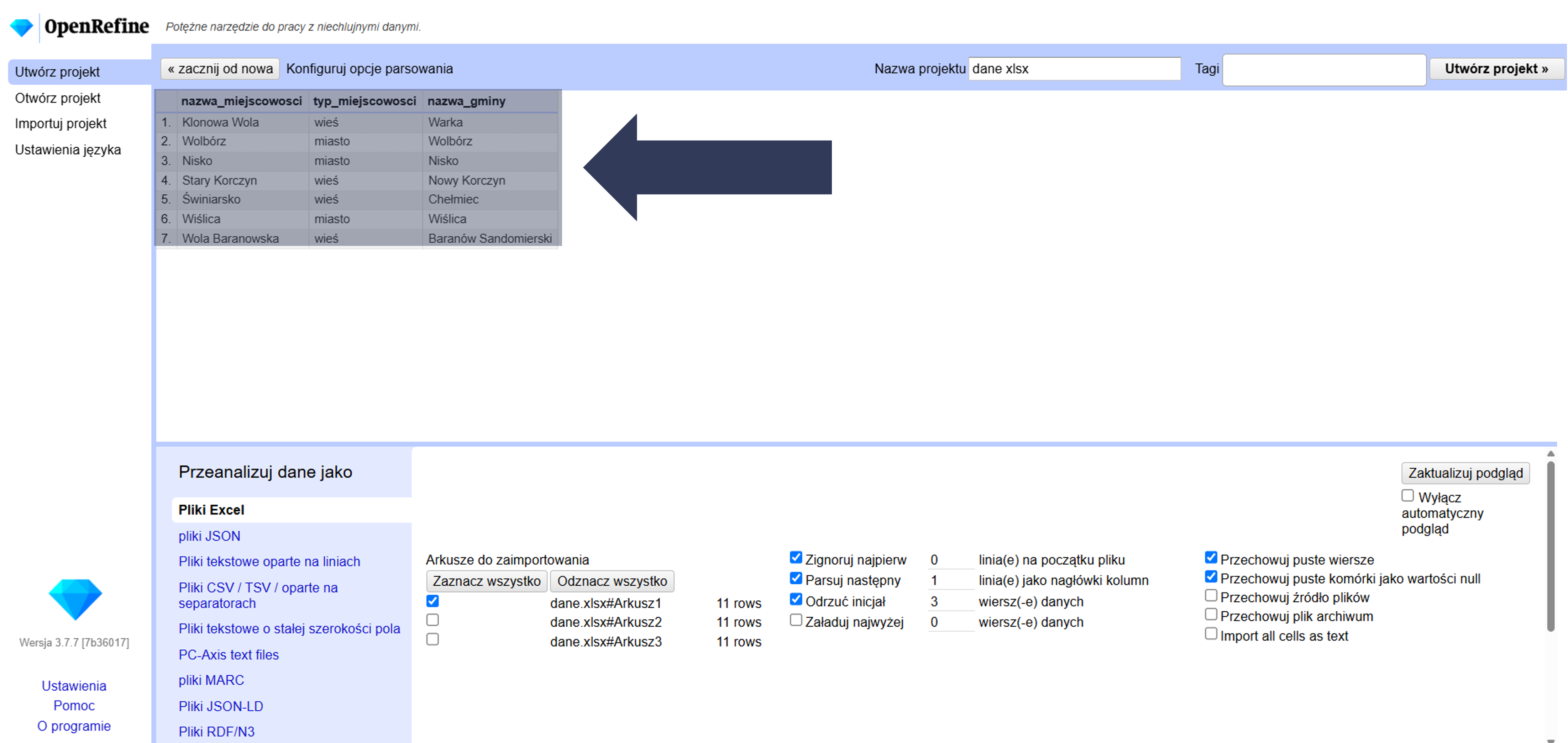
Wskazana liczba początkowych rekordów danych zostanie pominięta i nie trafi do projektu.
Uwaga: ta opcja różni się od kroku 8.2.4.1.2 (dotyczy dowolnych wierszy na początku pliku, np. opisów) oraz od Parsuj następny … jako nagłówki kolumn (ustawia wiersz/e jako nagłówki).
8.2.4.1.5 Ograniczenie liczby wczytywanych wierszy danych
Opcja Załaduj najwyżej … wierszy danych pozwala wczytać do projektu tylko pierwsze N wierszy danych. Przydatne do szybkiego testu importu/ustawień na małej próbce (np. 100 rekordów) przed załadowaniem całego pliku.
Aby ograniczyć liczbę wczytywanych wierszy danych:
- W sekcji Opcje importu zaznacz pole Załaduj najwyżej … wierszy danych.

- Wpisz w polu liczbowym maksymalną liczbę wierszy, które mają zostać zaimportowane.

- Sprawdź w podglądzie danych, czy widoczna jest tylko wybrana liczba wierszy.
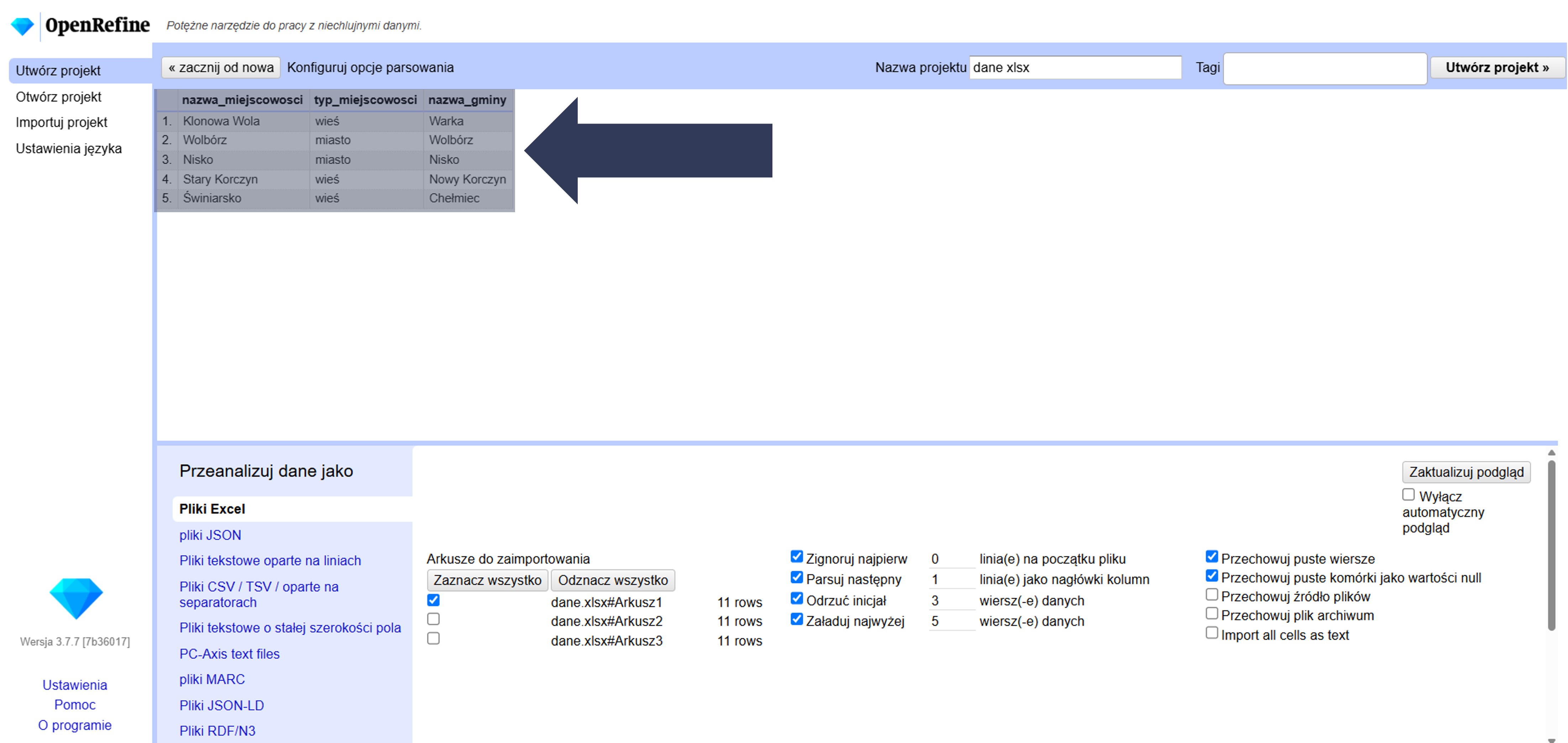
Do projektu zostanie wczytana ograniczona liczba rekordów (pierwsze N wierszy), co umożliwia testowanie konfiguracji importu bez ładowania całego pliku.
Uwaga: ograniczenie dotyczy tylko bieżącego importu i nie modyfikuje pliku źródłowego. Aby wczytać cały plik, odznacz tę opcję lub ustaw większą wartość.
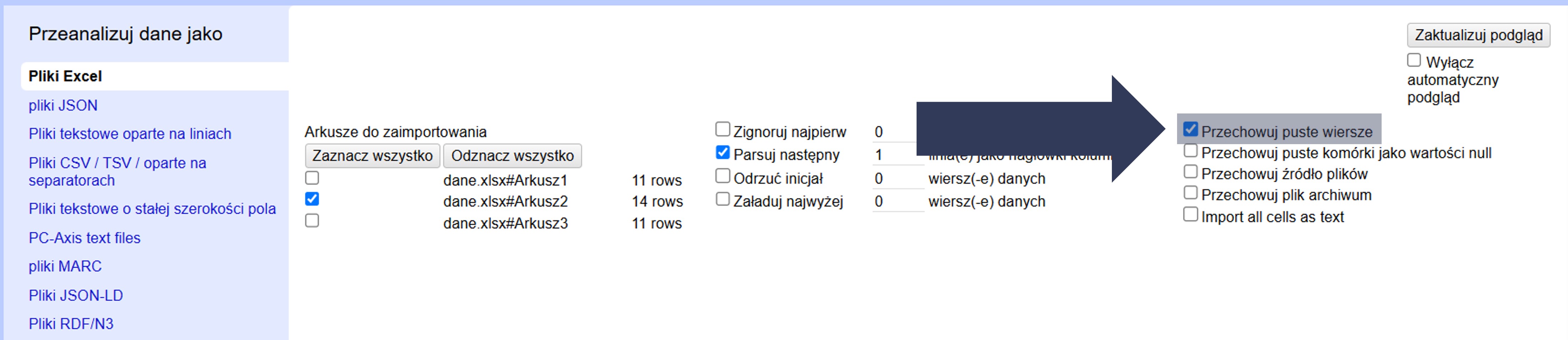
8.2.4.1.6 Przechowywanie pustych wierszy
W plikach danych mogą występować puste wiersze – celowo (np. dla rozdzielenia sekcji) lub przypadkowo. Ta opcja pozwala zdecydować, czy mają zostać zachowane w projekcie.
Aby zachować puste wiersze:
- W sekcji Opcje importu zaznacz pole Przechowuj puste wiersze.
- Sprawdź w podglądzie danych (górna część okna), czy puste wiersze są widoczne w strukturze projektu.
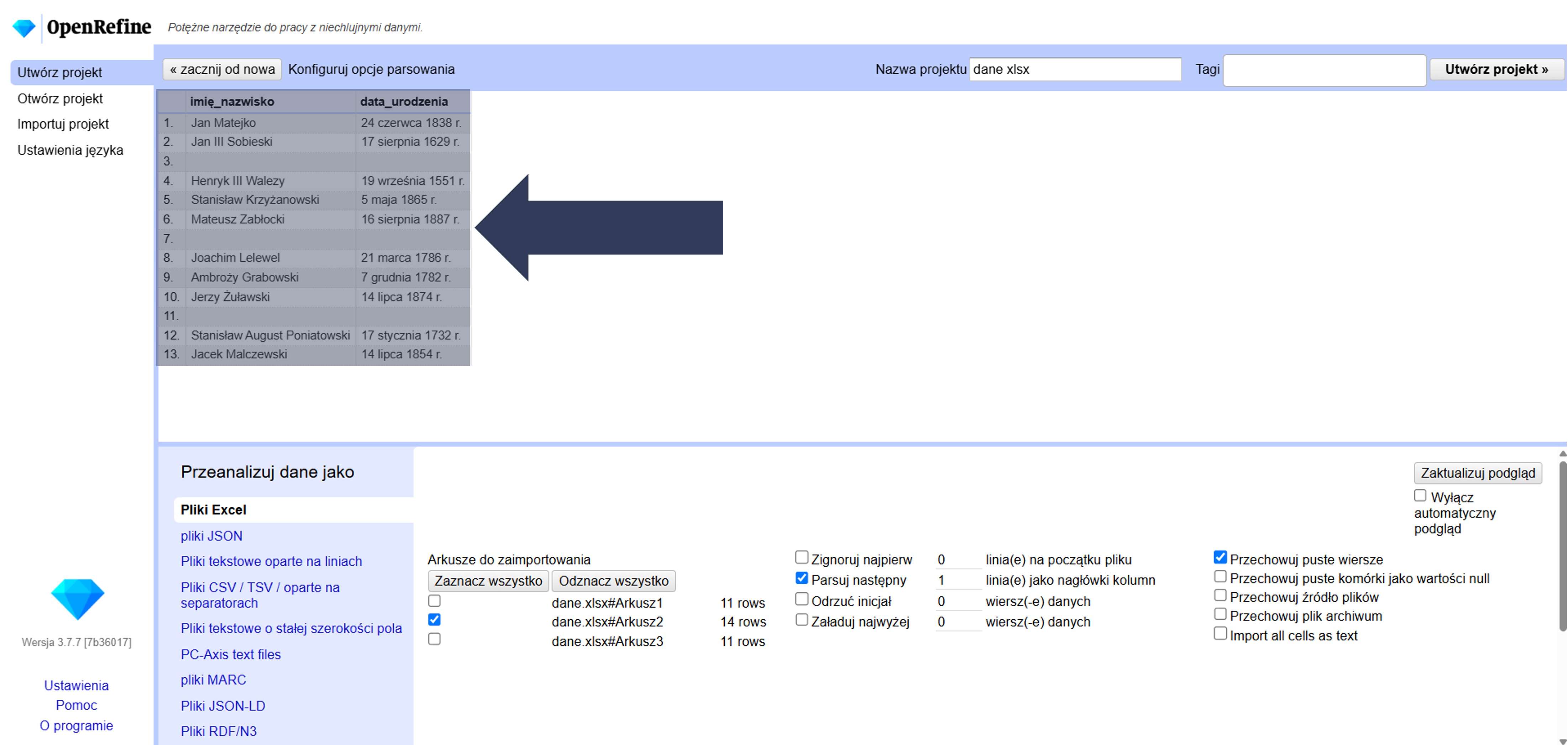
Puste wiersze zostaną zachowane w projekcie i będą widoczne między rekordami.
Uwaga: odznaczenie tej opcji spowoduje usunięcie pustych wierszy podczas importu. Zachowywanie pustych wierszy bywa pomocne przy zachowaniu układu sekcji, ale może utrudniać operacje liczenia/filtrowania.
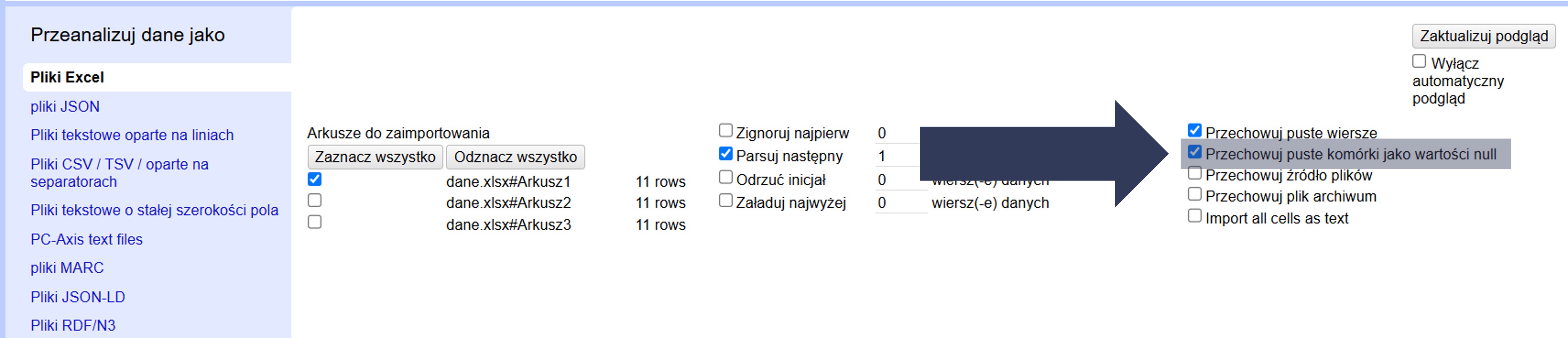
8.2.4.1.7 Interpretacja pustych pól
Puste pola w danych mogą być zapisane jako brak wartości (null) albo jako pusty tekst („”). To ustawienie decyduje, jak OpenRefine zapisze takie komórki.
Aby przechowywać puste komórki jako wartości null:
- W sekcji Opcje importu zaznacz pole Przechowuj puste komórki jako wartości null.
- Sprawdź w podglądzie danych, czy puste pola są oznaczone jako null, a nie jako pusty tekst.
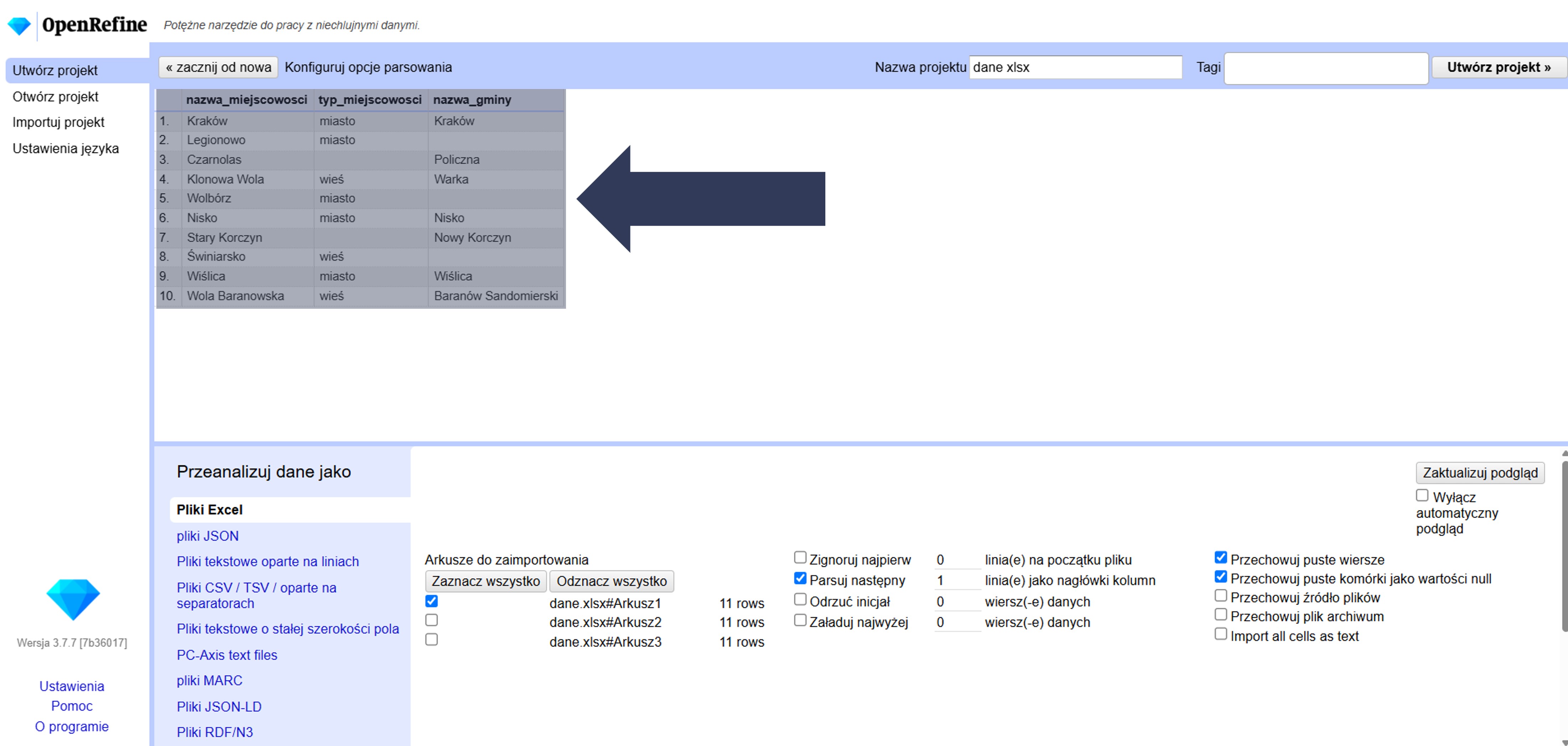
Puste komórki zostaną zapisane jako null (brak wartości), co wpływa m.in. na fasety, filtrowanie i operacje typu „usuń wiersze z brakami”.
Uwaga: odznaczenie tej opcji spowoduje zapis pustych pól jako pustych ciągów („”), które są traktowane jak tekst (mogą pojawiać się w fasetach jako osobna wartość).
8.2.4.1.8 Przechowywanie pliku źródłowego w katalogu projektu
Domyślnie OpenRefine tworzy projekt na podstawie danych wejściowych. Możesz dodatkowo zachować oryginalny plik źródłowy w katalogu projektu (dla odtwarzalności i audytu).
Aby zachować oryginalny plik źródłowy w katalogu projektu:
- W sekcji Opcje importu zaznacz pole Przechowuj źródło plików.
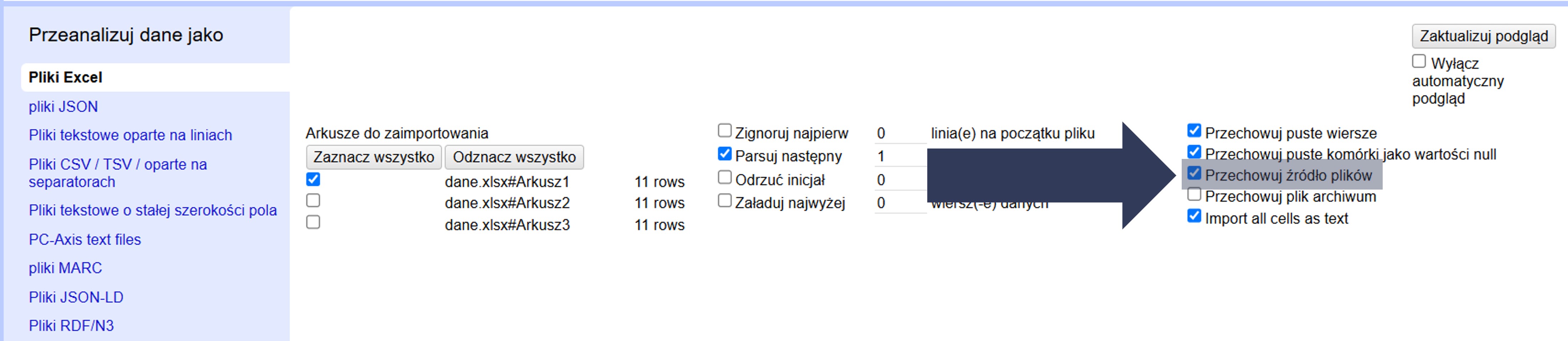
- Po imporcie sprawdź w katalogu projektu, czy plik źródłowy został zapisany wraz z danymi projektu.
Oryginalny plik zostanie dołączony do projektu, co ułatwia weryfikację i ponowne przetwarzanie danych.
Uwaga: włączenie tej opcji zwiększa zużycie miejsca na dysku (kopiowany jest pełny plik źródłowy).
8.2.4.1.9 Przechowywanie archiwum źródłowego w projekcie
Czasem dane są wgrywane z archiwum (np. ZIP). OpenRefine może zachować cały plik archiwum w katalogu projektu, aby w każdej chwili móc wrócić do oryginalnego pakietu danych.
Aby przechowywać całe archiwum w projekcie:
- W sekcji Opcje importu zaznacz pole Przechowuj plik archiwum.
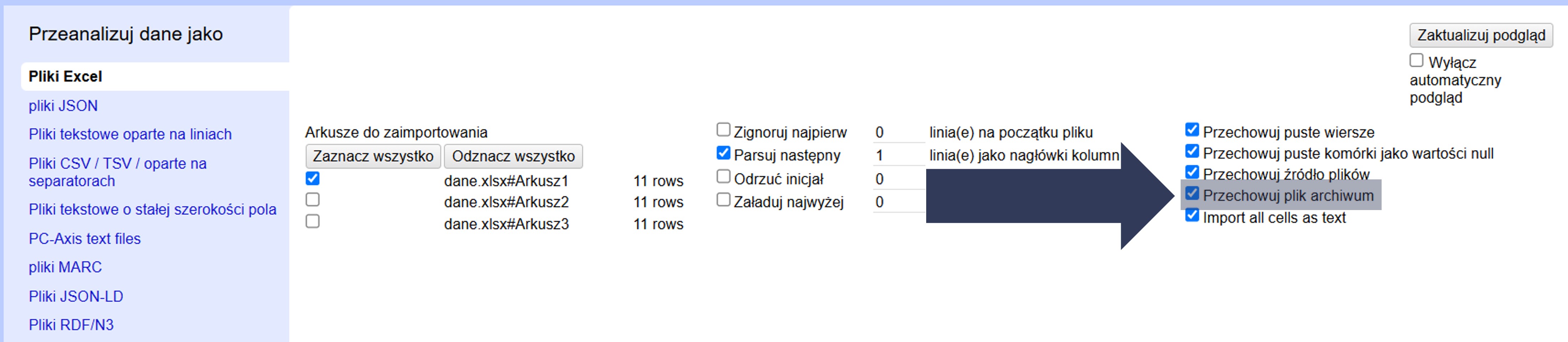
- Po imporcie sprawdź w podglądzie oraz w katalogu projektu, czy archiwum zostało dołączone do projektu.
Oryginalny plik ZIP (lub inne archiwum) zostanie zachowany wraz z projektem — ułatwia to audyt i odtwarzalność procesu.
Uwaga: włączenie tej opcji może zwiększyć rozmiar projektu (przechowywany jest pełny plik archiwum, oprócz wyodrębnionych danych).
8.2.4.1.10 Import wszystkich komórek jako tekst (wyłączenie automatycznego rozpoznawania typów)
OpenRefine domyślnie próbuje rozpoznawać typy danych (np. liczby, daty). Może to prowadzić do błędów, np. potraktowania kodu jako daty. Ta opcja wymusza traktowanie wszystkich wartości jako zwykły tekst.
Aby wymusić traktowanie wszystkich wartości jako tekst:
- W sekcji Opcje importu zaznacz pole Import all cells as text.
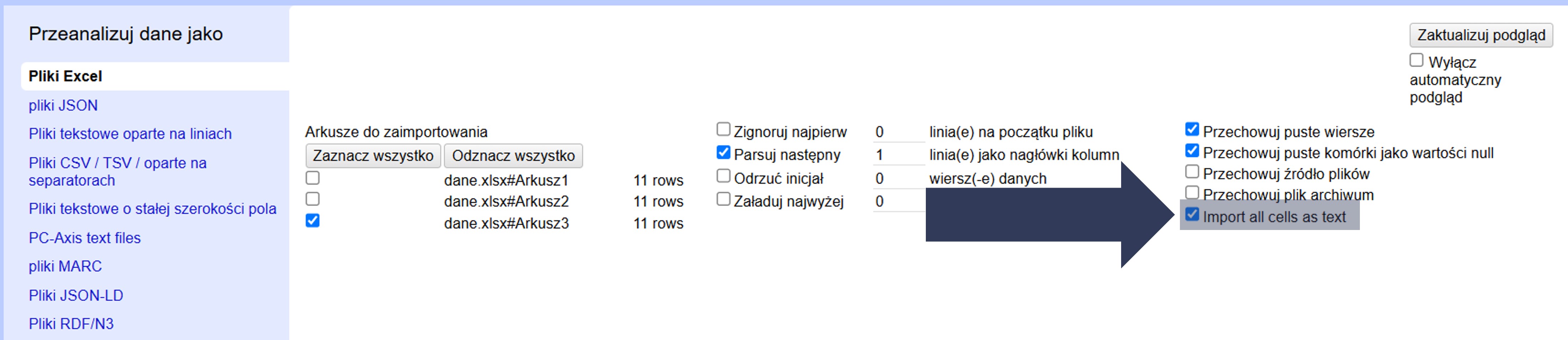
- Sprawdź w podglądzie danych, czy wszystkie wartości zostały zaimportowane jako tekst (bez automatycznej interpretacji typów).
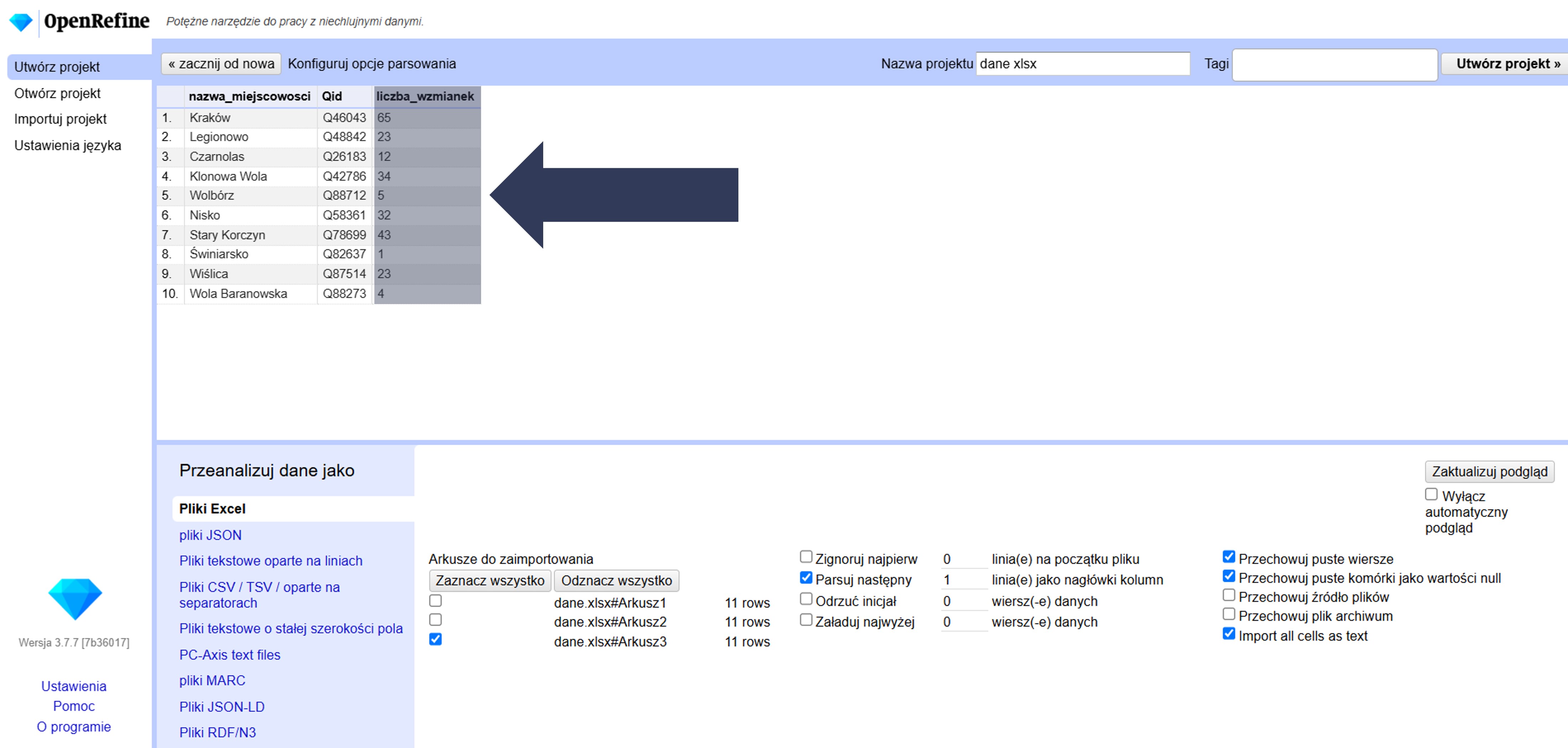
Wszystkie komórki zostaną wczytane jako łańcuchy znaków. OpenRefine nie będzie próbował automatycznie rozpoznawać liczb, dat itp.
Uwaga: po imporcie możesz selektywnie konwertować wybrane kolumny do dat/liczb, aby odzyskać odpowiednie typy tylko tam, gdzie to potrzebne.
8.2.4.2 Podgląd i konfiguracja importu danych z plików CSV/TSV/opartych na separatorach
8.2.4.2.1 Ustawienie kodowania znaków
Aby ustawić kodowanie znaków:
- W sekcji Opcje importu kliknij pole Kodowanie znaków.
- Z listy wybierz żądane kodowanie (np. UTF-8, Windows-1250, ISO-8859-2).
- Sprawdź w podglądzie danych, czy polskie znaki wyświetlają się poprawnie.
Wybrane kodowanie zostanie zastosowane w projekcie i użyte przy wczytywaniu danych.
Wskazówki:
• Jeśli widzisz „krzaczki” zamiast polskich znaków, spróbuj Windows-1250 lub ISO-8859-2.
• Większość współczesnych plików CSV używa UTF-8 (czasem z BOM).
8.2.4.2.2 Ustawienie separatora kolumn
Aby ustawić separator kolumn:
- W sekcji Opcje importu znajdź ustawienie Kolumny są oddzielone.
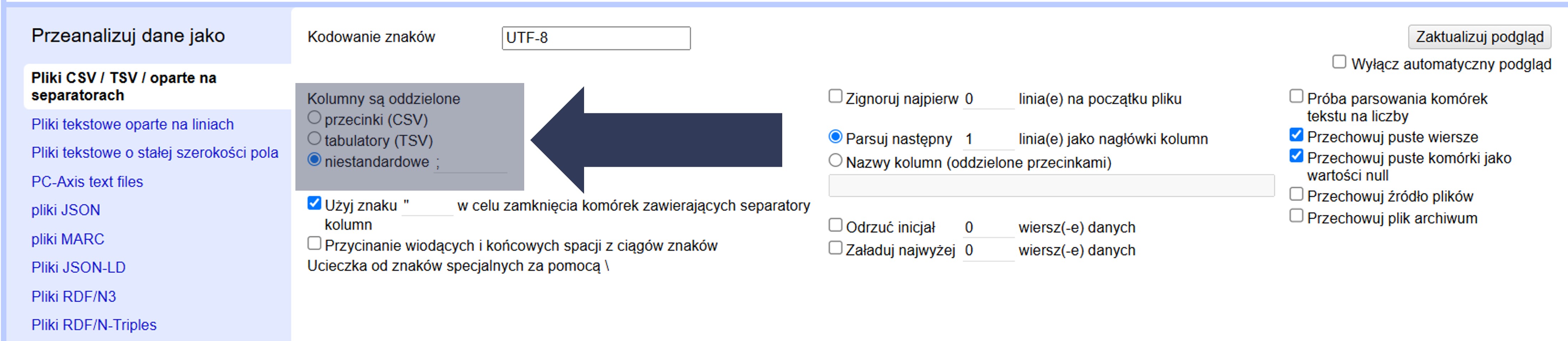
- Wybierz jedną z opcji poniżej i sprawdź podgląd danych.
- Przecinki (CSV) – wartości są dzielone po przecinku. Wartości ujęte w cudzysłowie pozostają w całości (np. "Kraków, Nowa Huta" nie zostanie rozbite).
- Tabulatory (TSV) – wartości są dzielone po znaku tabulacji.
- Niestandardowe – zaznacz i wpisz znak separatora w polu obok. Wartości będą dzielone po wskazanym znaku.
Wskazówki:
• Jeśli wartości zawierają znak separatora, ujmij je w cudzysłowie w pliku źródłowym — OpenRefine respektuje cudzysłowy.
• Po zmianie opcji zawsze zweryfikuj podgląd: nagłówki i kolumny powinny wyglądać poprawnie.
8.2.4.2.3 Znak domknięcia komórek zawierających separator
Wartości ujęte w podany znak (np. " albo ') są traktowane jako jedna komórka, nawet jeśli w środku mają znak separatora (np. przecinek w CSV).
Aby określić znak domknięcia komórek zawierających separator:
- Zaznacz Użyj znaku … w celu zamknięcia komórek zawierających separatory kolumn.
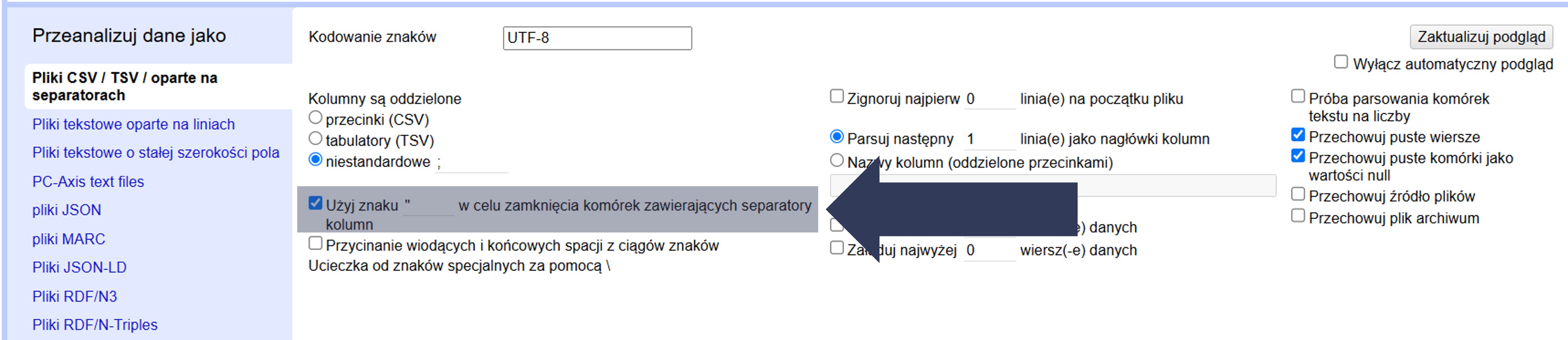
- Wpisz w polu znak cytowania używany w pliku (np. " albo ').
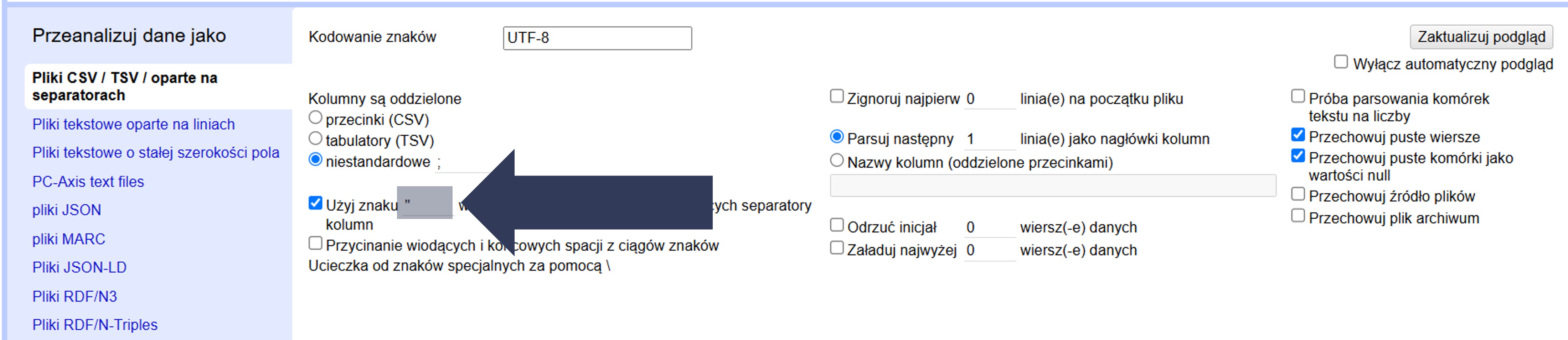
- Sprawdź podgląd danych – wartości w cudzysłowie/apostrofach nie powinny się rozbijać.
Podczas importu wartości otoczone wskazanym znakiem cytowania będą wczytane jako pojedyncze komórki (separator wewnątrz nie rozbije wartości); sam znak cytowania zostanie potraktowany zgodnie z ustawieniami ucieczki (np. "" lub \").
Uwagi:
• Jeśli plik nie używa cytowania, odznacz tę opcję lub pozostaw pole puste.
• Gdy jako znak cytowania używasz " i nie zaznaczysz Ucieczka od znaków specjalnych za pomocą \, to znak " wewnątrz wartości zapisuje się podwójnie: "" (standard CSV).
8.2.4.2.4 Przycinanie wiodących i końcowych spacji z ciągów znaków
Opcja usuwa spacje (oraz tabulatory) na początku i na końcu każdej wartości podczas importu. Zapobiega „niewidzialnym” różnicom, które psują fasety, sortowanie i dopasowania. Wyłącz tę opcję tylko, gdy spacje brzegowe są znaczące (rzadkie przypadki, np. dane o stałej szerokości pól).
Aby włączyć przycinanie:
- W sekcji Opcje importu zaznacz Przycinanie wiodących i końcowych spacji z ciągów znaków.
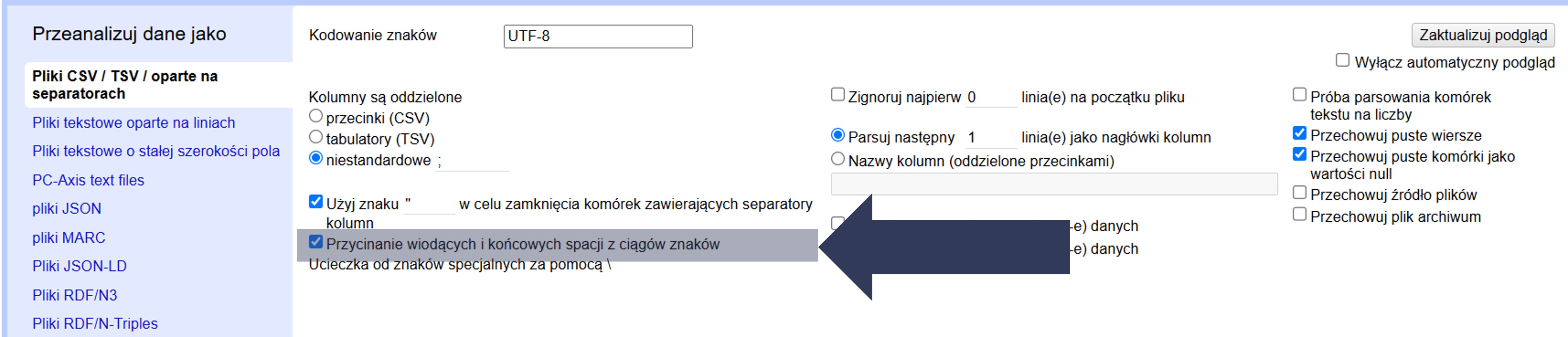
- Sprawdź podgląd danych, czy wartości nie mają już spacji na początku/końcu.
Wartości są wczytywane bez spacji brzegowych; spacje wewnątrz tekstu nie są ruszane.
8.2.4.2.5 Ignorowanie początkowych linii arkusza danych
Jeśli na początku pliku znajdują się dodatkowe opisy, nagłówki techniczne, notatki lub inne metadane, możesz je pominąć, wskazując liczbę wierszy do odrzucenia.
Aby odrzucić z importu dane wiersze:
- W sekcji Opcje importu zaznacz pole Zignoruj najpierw … linia(e) na początku pliku.
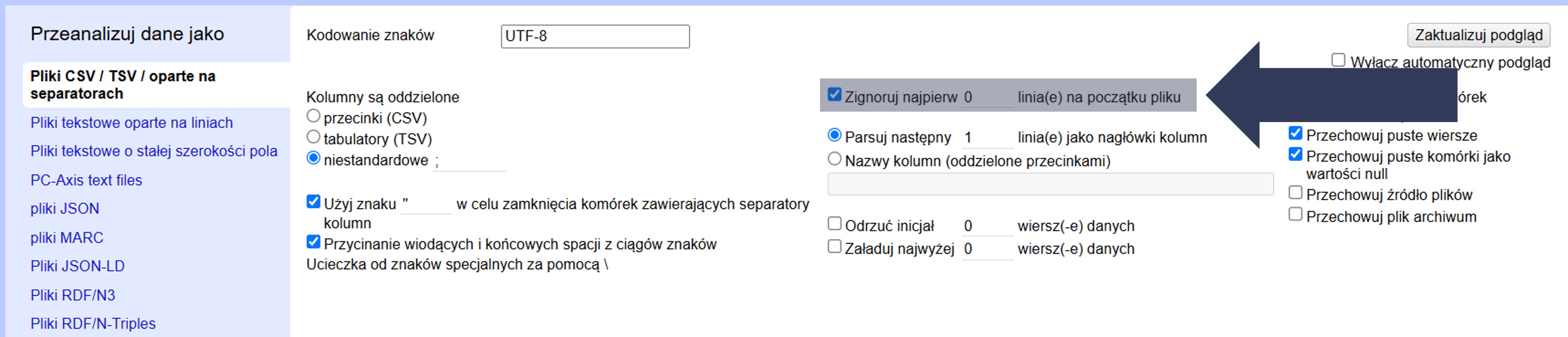
- Wpisz w polu liczbowym liczbę wierszy, które mają zostać pominięte.
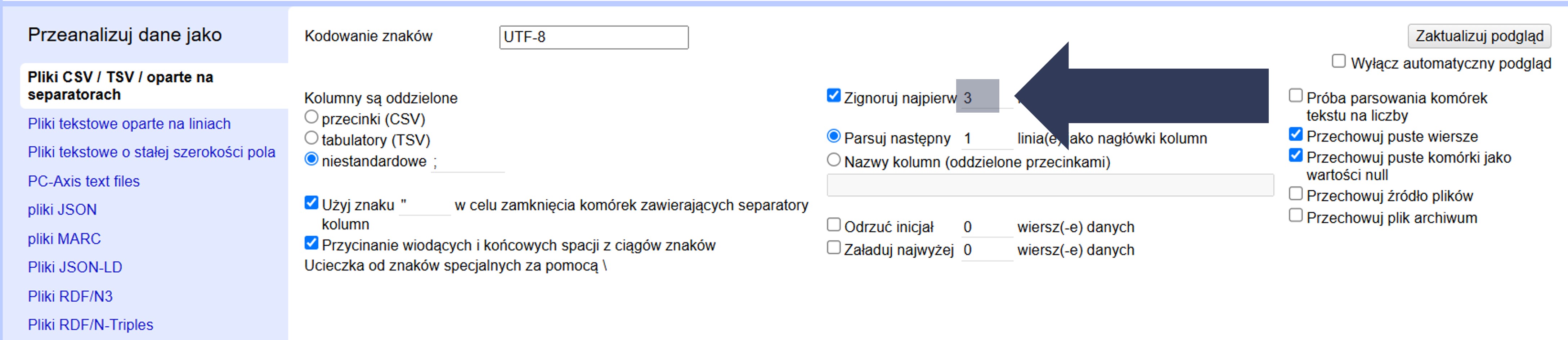
- Opcjonalnie: Pozostaw 0, aby wczytać wszystkie wiersze od początku.
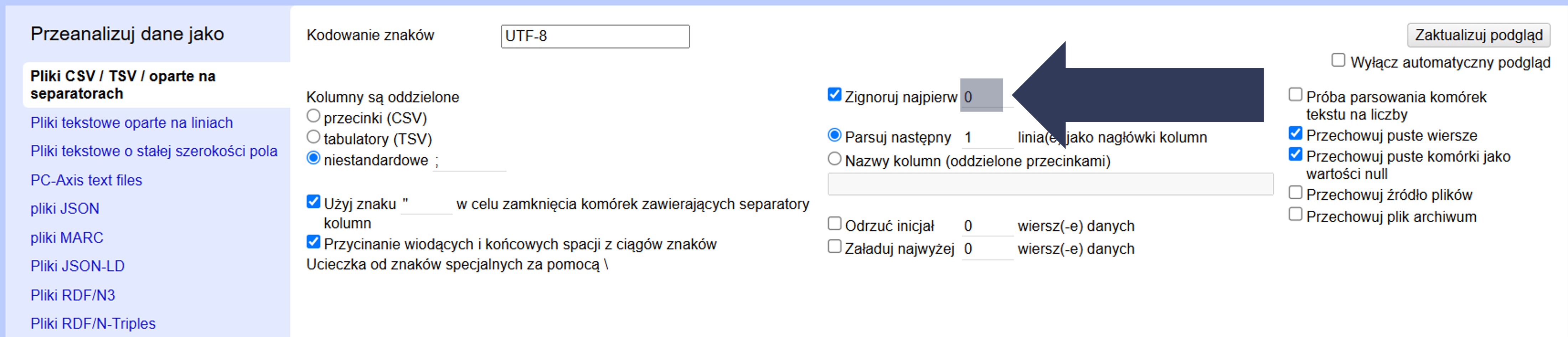
- Sprawdź w podglądzie danych, czy import rozpoczyna się od właściwego wiersza.
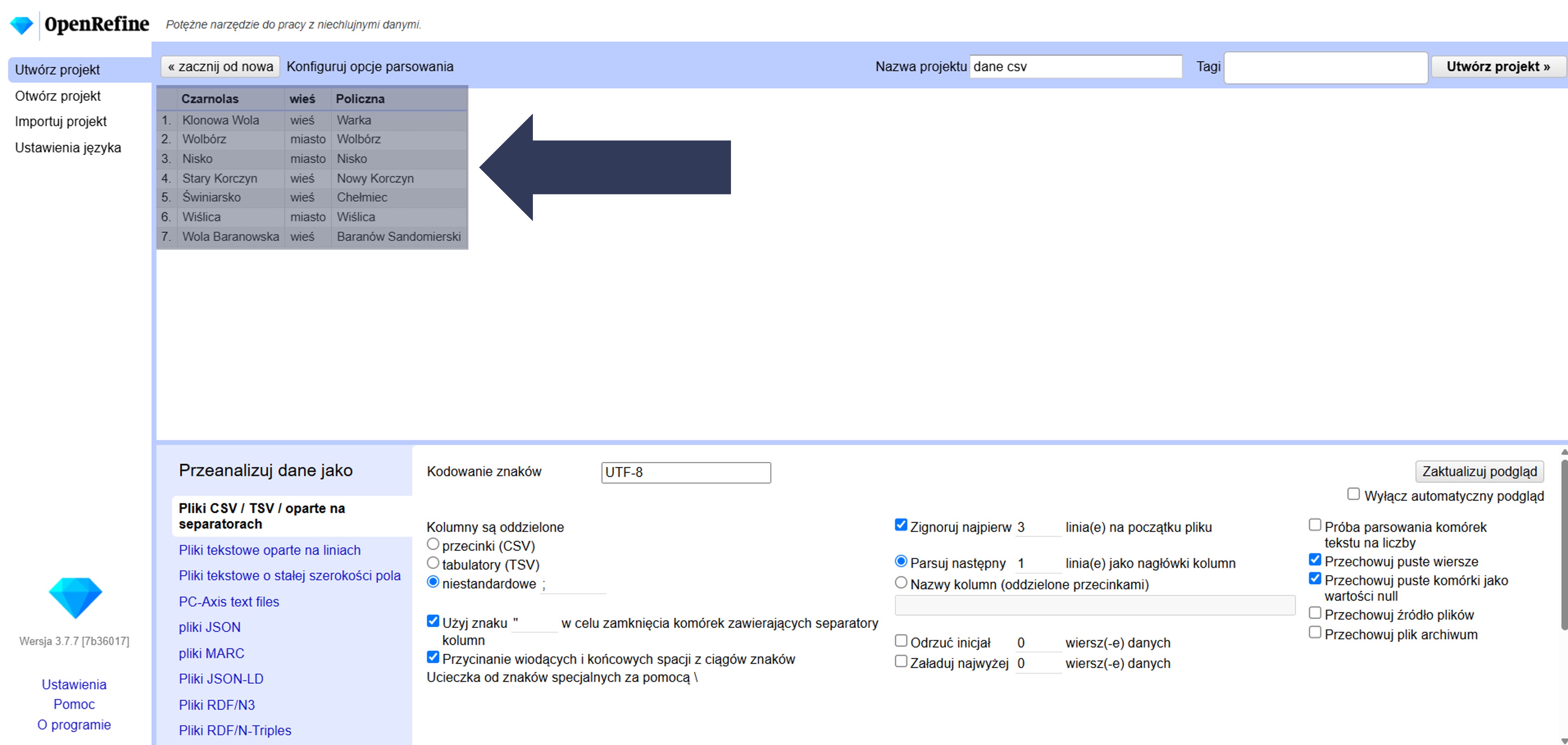
Wskazana liczba początkowych wierszy zostanie pominięta i nie trafi do projektu.
8.2.4.2.6 Ustawienia początkowych linii jako nazw kolumn
Jeśli pierwszy wiersz pliku zawiera nazwy kolumn, a dopiero od drugiego zaczynają się dane, zaznacz opcję Parsuj następny … jako nagłówki kolumn.
Aby ustawić pierwszy wiersz jako nagłówki kolumn:
- W sekcji Opcje importu zaznacz pole Parsuj następny … jako nagłówki kolumn.
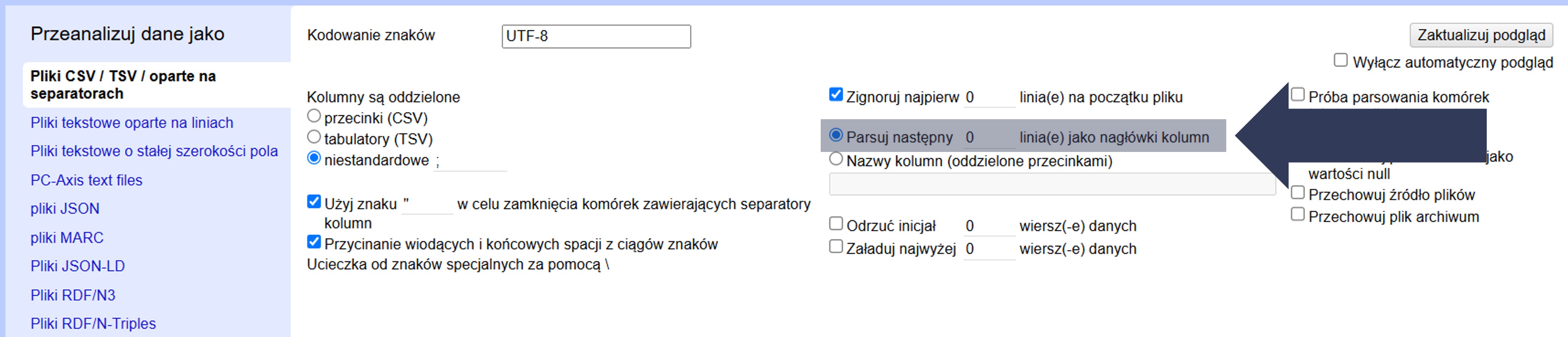
- W polu liczbowym obok pozostaw 1, jeśli nagłówki są w pierwszym wierszu danych.
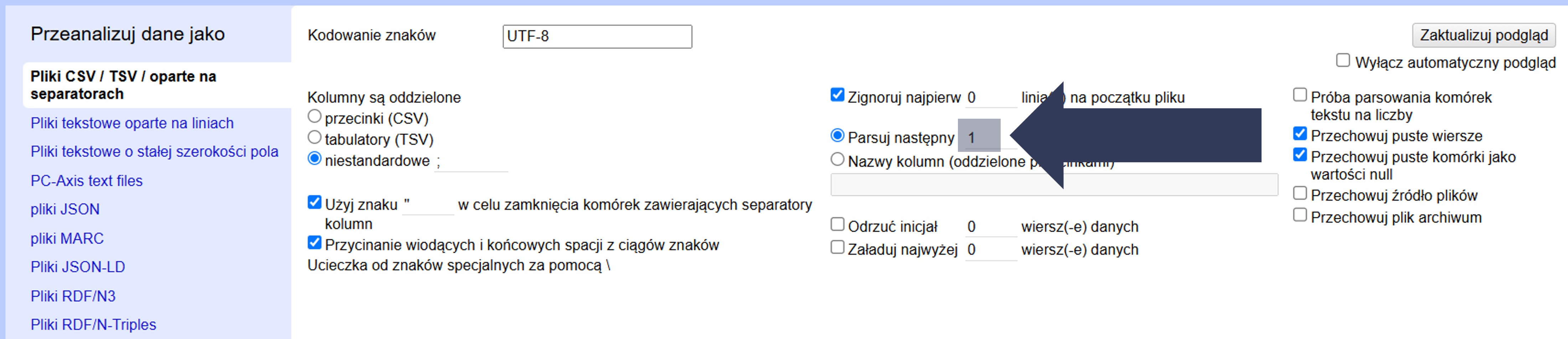
- Opcjonalnie: Wpisz inną wartość, jeśli nagłówki znajdują się dalej (np. 2).
- Sprawdź w podglądzie danych (góra okna), czy kolumny mają poprawne nazwy.
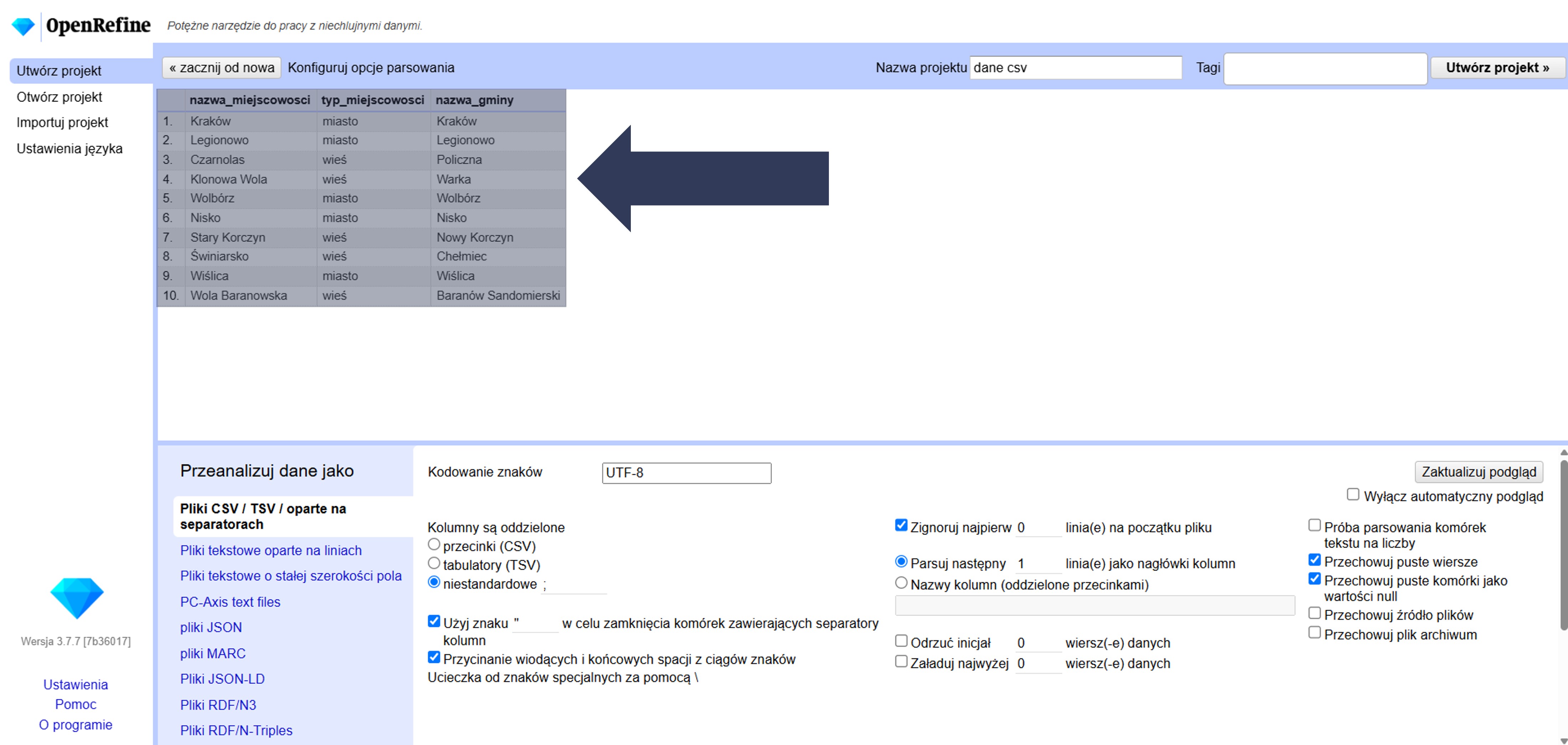
Wskazany wiersz zostanie użyty jako nagłówki kolumn, a sam wiersz nie trafi do danych.
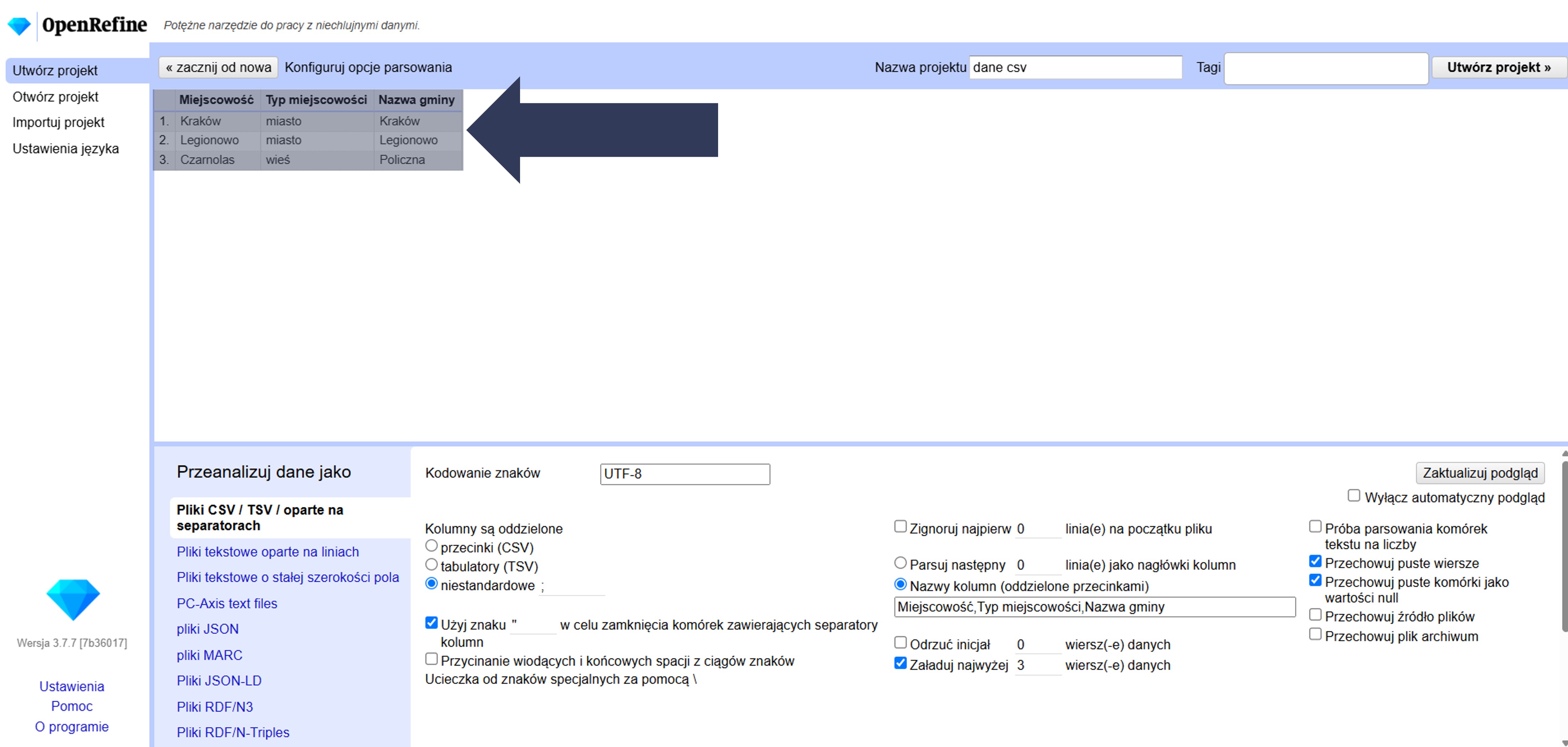
8.2.4.2.7 Ręcznie nadawanie nazw nagłówkom kolumn podczas importu
Opcja pozwala ręcznie nadać nagłówki kolumn podczas importu – przydaje się, gdy plik nie ma wiersza nagłówków lub nagłówki w pliku są błędne/niechciane i chcesz je nadpisać.
Aby nadać nazwy nagłówkom kolumn podczas importu:
- Zaznacz opcję Nazwy kolumn (oddzielone przecinkami).
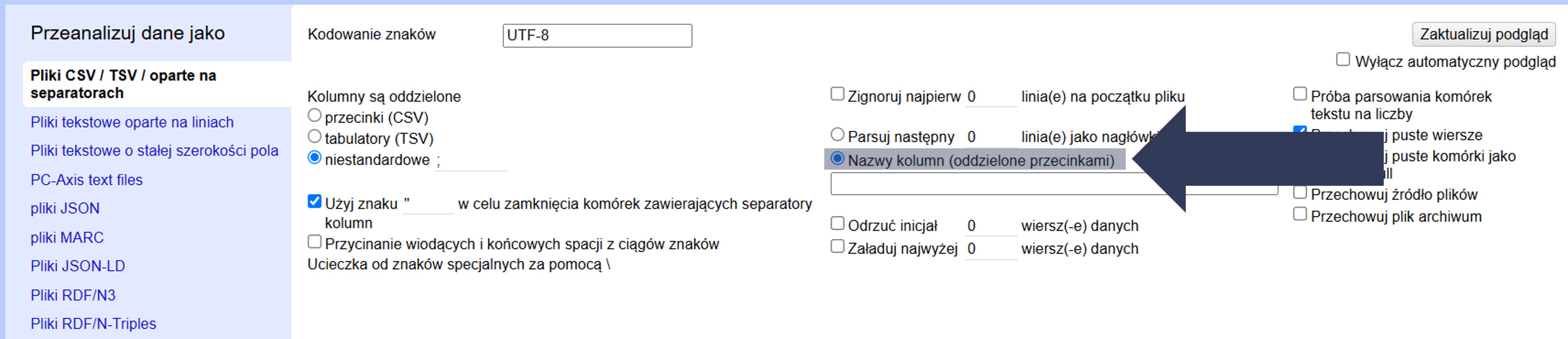
- W polu poniżej wpisz listę nazw po przecinku, w kolejności kolumn, np.:
Miejscowość,Typ miejscowości,Nazwa gminy
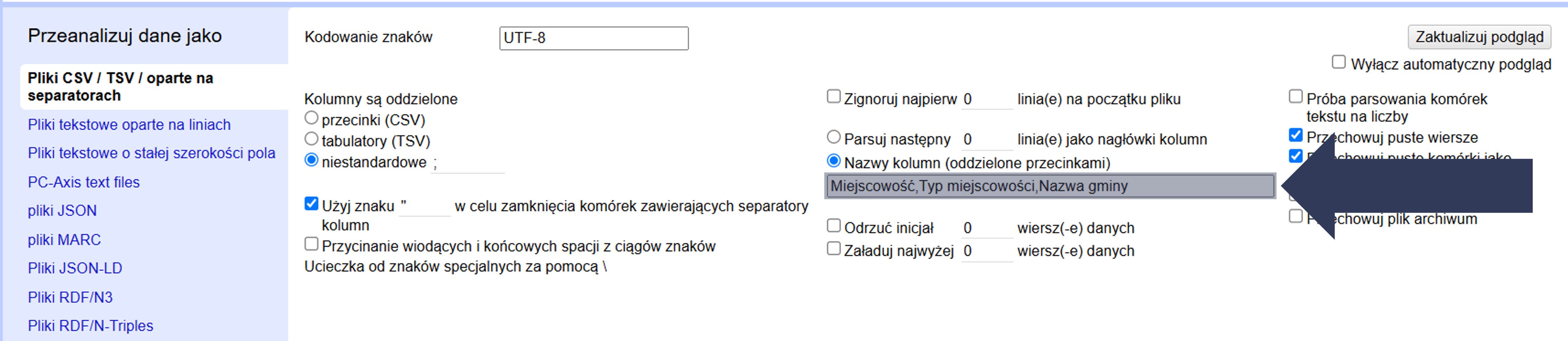
- Sprawdź podgląd – kolumny powinny mieć podane nazwy.
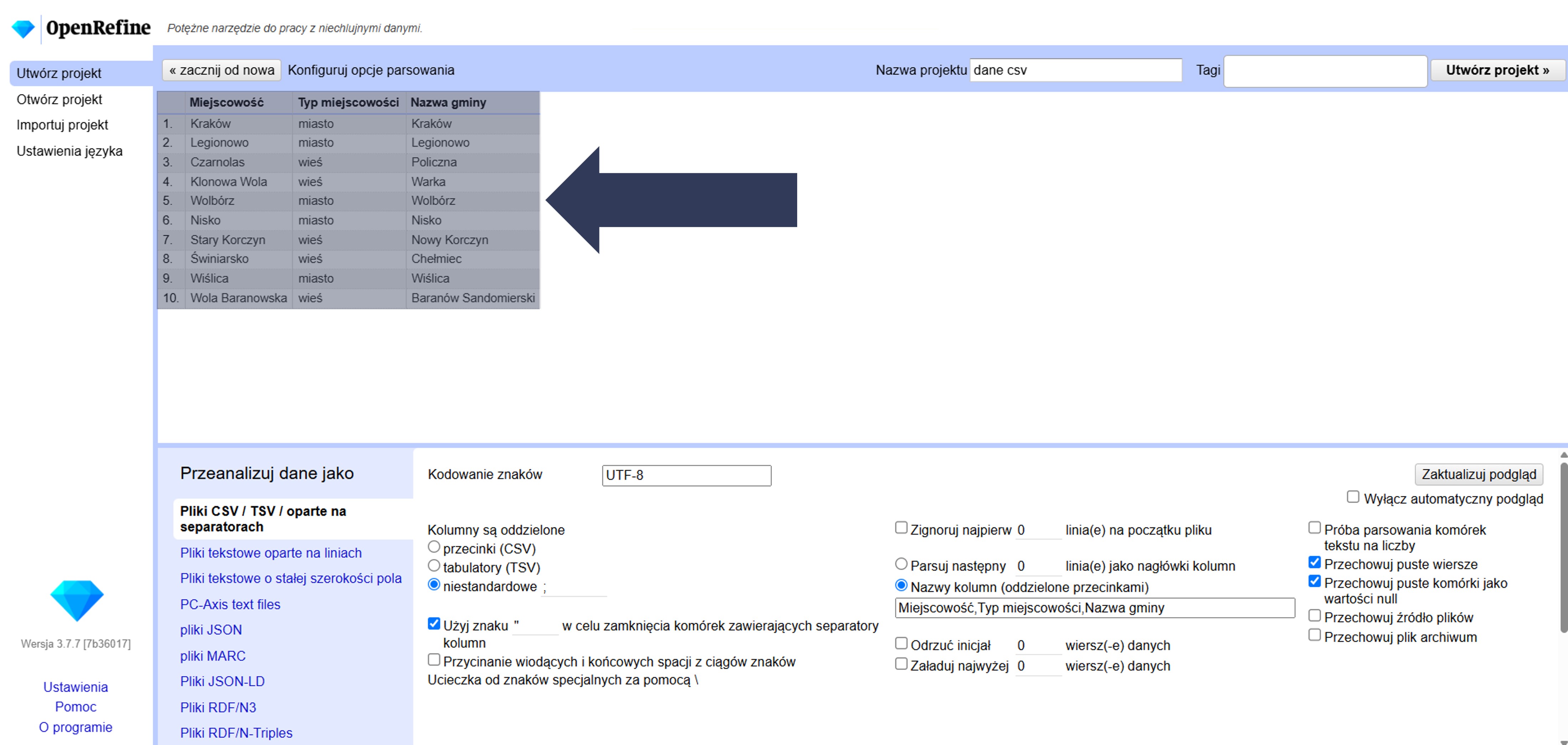
OpenRefine zastosuje wpisane nazwy jako nagłówki. Wiersze z pliku nie będą użyte jako nagłówki (stają się zwykłymi danymi).
Uwagi:
• Jeśli podasz mniej nazw niż kolumn, pozostałe otrzymają nazwy domyślne (np. „Column 5”).
• Jeśli podasz więcej nazw, nadmiar zostanie zignorowany.
• Nazwy najlepiej wpisywać bez przecinków (to separator listy).
8.2.4.2.8 Odrzucenie początkowych wierszy danych (nie nagłówków)
Opcja Odrzuć inicjał … wierszy danych pozwala pominąć pierwsze wiersze właściwych danych (nie dotyczy nagłówków). Stosuj w sytuacjach wyjątkowych, np. gdy początkowe rekordy są błędne, testowe lub nie powinny znaleźć się w projekcie.
Aby odrzucić początkowe wiersze danych z importu:
- W sekcji Opcje importu zaznacz pole Odrzuć inicjał … wierszy danych.
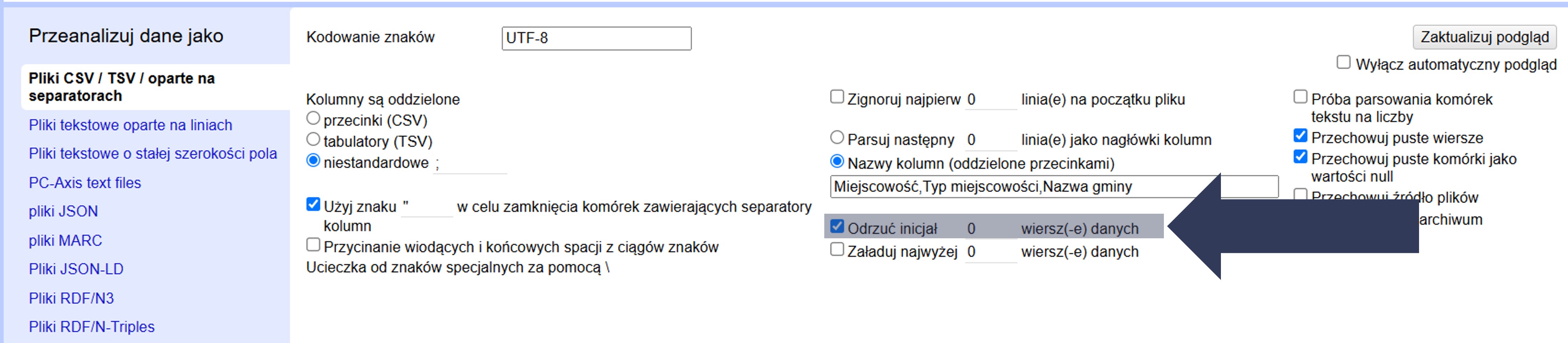
- Wpisz w polu liczbowym liczbę wierszy, które mają zostać pominięte.
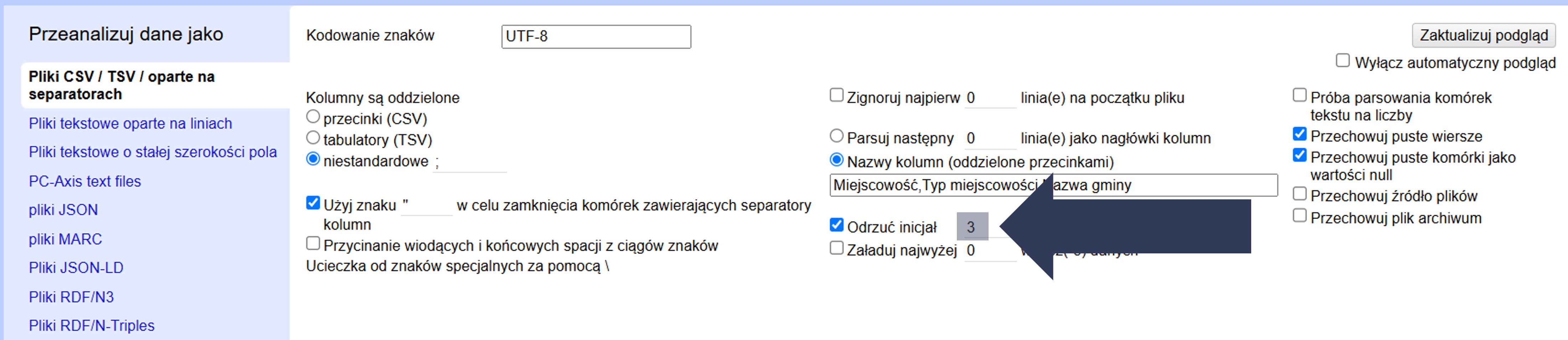
- Sprawdź w podglądzie danych (górna część okna), czy wiersze zostały odrzucone i import zaczyna się od właściwego miejsca.
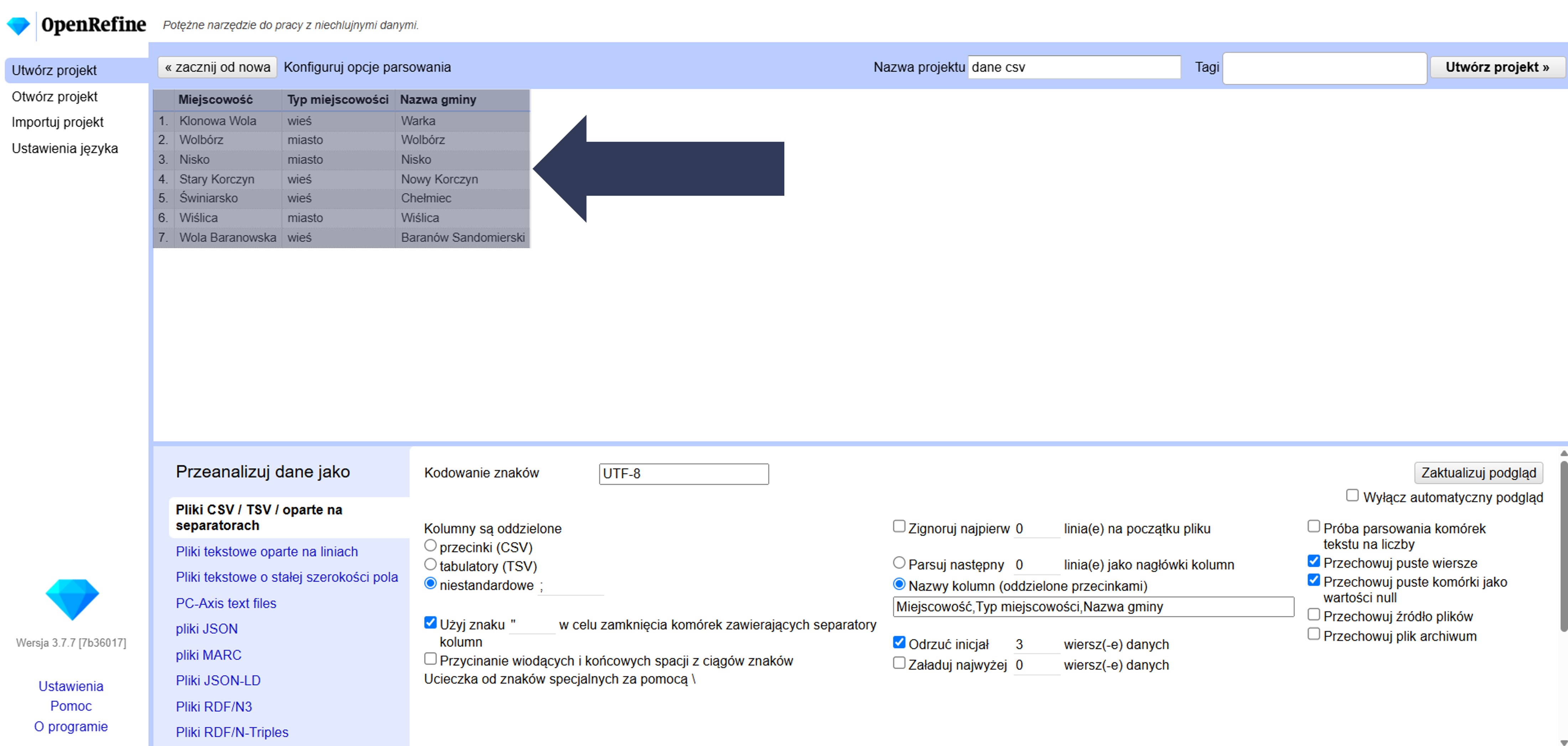
Wskazana liczba początkowych rekordów danych zostanie pominięta i nie trafi do projektu.
Uwaga: ta opcja różni się od kroku 8.2.4.2.5 (dotyczy dowolnych wierszy na początku pliku, np. opisów) oraz od Parsuj następny … jako nagłówki kolumn (ustawia wiersz jako nagłówki).
8.2.4.2.9 Ograniczenie liczby wczytywanych wierszy danych
Opcja Załaduj najwyżej … wierszy danych pozwala wczytać do projektu tylko pierwsze N wierszy danych. Przydatne do szybkiego testu importu/ustawień na małej próbce (np. 100 rekordów) przed załadowaniem całego pliku.
Aby ograniczyć liczbę wczytywanych wierszy danych:
- W sekcji Opcje importu zaznacz pole Załaduj najwyżej … wierszy danych.
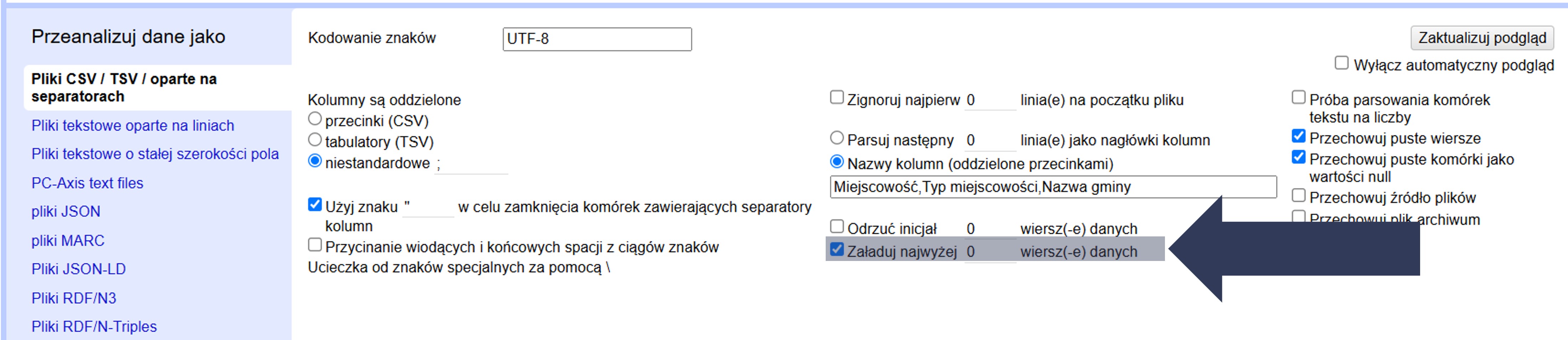
- Wpisz w polu liczbowym maksymalną liczbę wierszy, które mają zostać zaimportowane.
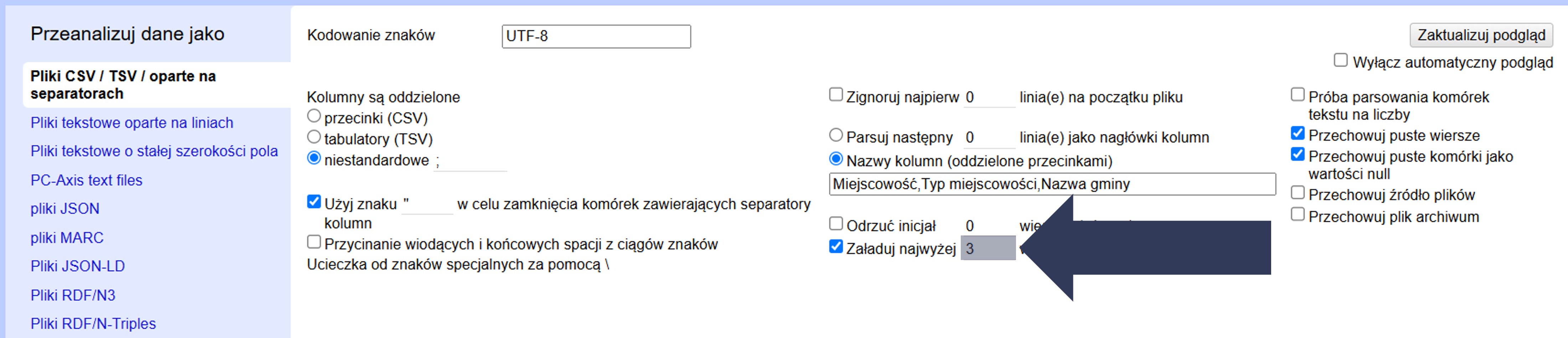
- Sprawdź w podglądzie danych, czy widoczna jest tylko wybrana liczba wierszy.
Do projektu zostanie wczytana ograniczona liczba rekordów (pierwsze N wierszy), co umożliwia testowanie konfiguracji importu bez ładowania całego pliku.
Uwaga: ograniczenie dotyczy tylko bieżącego importu i nie modyfikuje pliku źródłowego. Aby wczytać cały plik, odznacz tę opcję lub ustaw większą wartość.
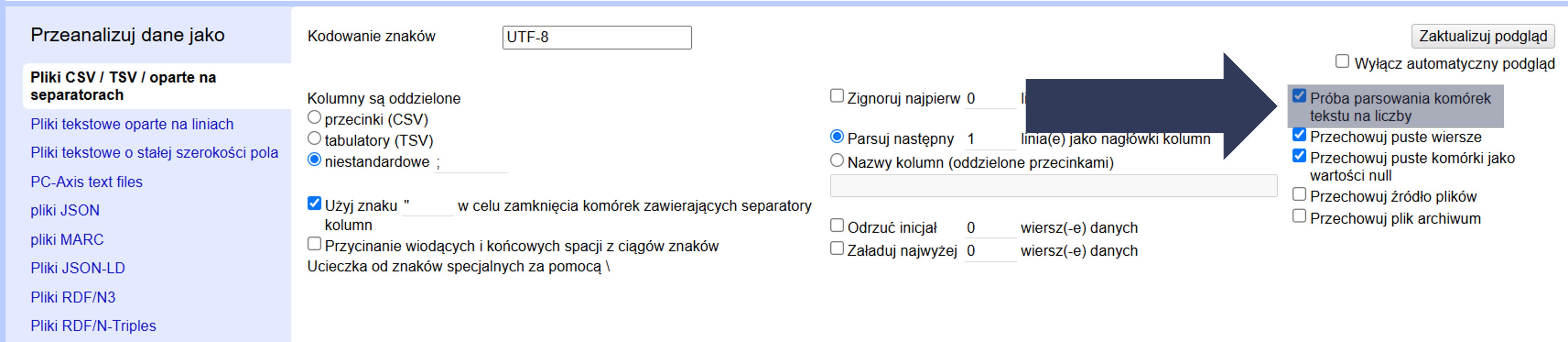
8.2.4.2.10 Próba parsowania komórek tekstu na liczby
Opcja „Próba parsowania komórek tekstu na liczby” sprawia, że podczas importu OpenRefine rozpoznaje teksty wyglądające na liczby (np. 42, −7, 3.14, 1e−3) i zamienia je na typ liczbowy; pozostałe wartości zostają tekstem. Dzięki temu od razu można używać faset numerycznych, sortowania liczbowego i filtrów zakresu. Włączaj ją dla kolumn z pomiarami/ilościami (kwoty, lata, współrzędne), a wyłączaj dla identyfikatorów i kodów, gdzie istotne są zera wiodące lub format (PESEL, kody pocztowe, NIP/REGON, telefony, sygnatury), bo „00123” zamieni się na „123”. Zwróć też uwagę na zapis dziesiętny: parser najlepiej rozumie kropkę (3.14); wartości z przecinkiem (12,50) mogą pozostać tekstem — w razie potrzeby po imporcie zamień przecinek na kropkę i rzutuj na liczbę.
Aby włączyć próbę parsowania:
- W sekcji Opcje importu zaznacz Próba parsowania komórek tekstu na liczby.
- Sprawdź podgląd danych, czy kolumny liczbowe są poprawnie rozpoznane.
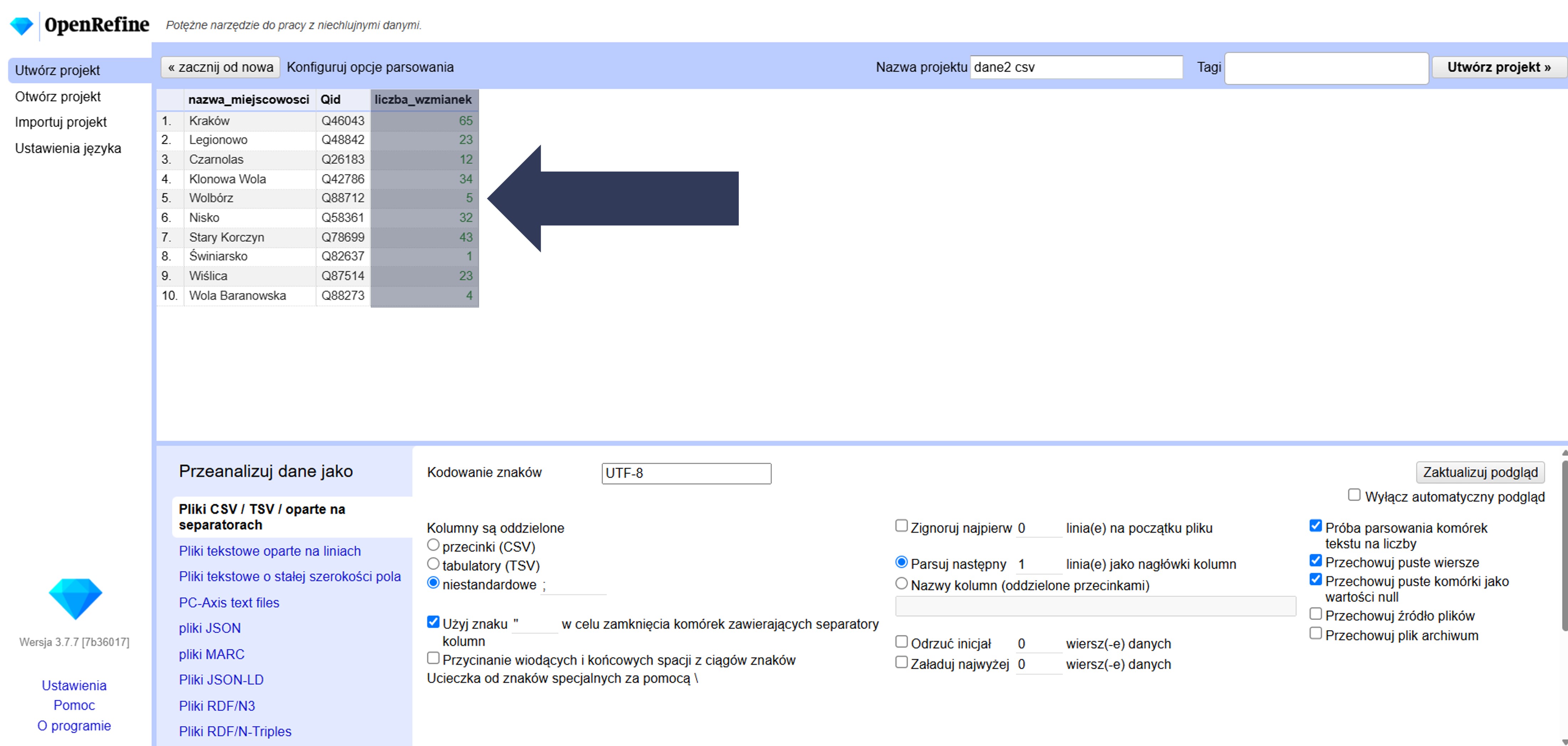
Rozpoznane wartości stają się liczbami (możesz od razu używać faset numerycznych i zakresów). Jeśli coś zostało zinterpretowane niezgodnie z oczekiwaniem, odznacz opcję i zaimportuj ponownie albo po imporcie zmieniaj typ selektywnie.
8.2.4.2.11 Przechowywanie pustych wierszy
W plikach danych mogą występować puste wiersze – celowo (np. dla rozdzielenia sekcji) lub przypadkowo. Ta opcja pozwala zdecydować, czy mają zostać zachowane w projekcie.
Aby zachować puste wiersze:
- W sekcji Opcje importu zaznacz pole Przechowuj puste wiersze.
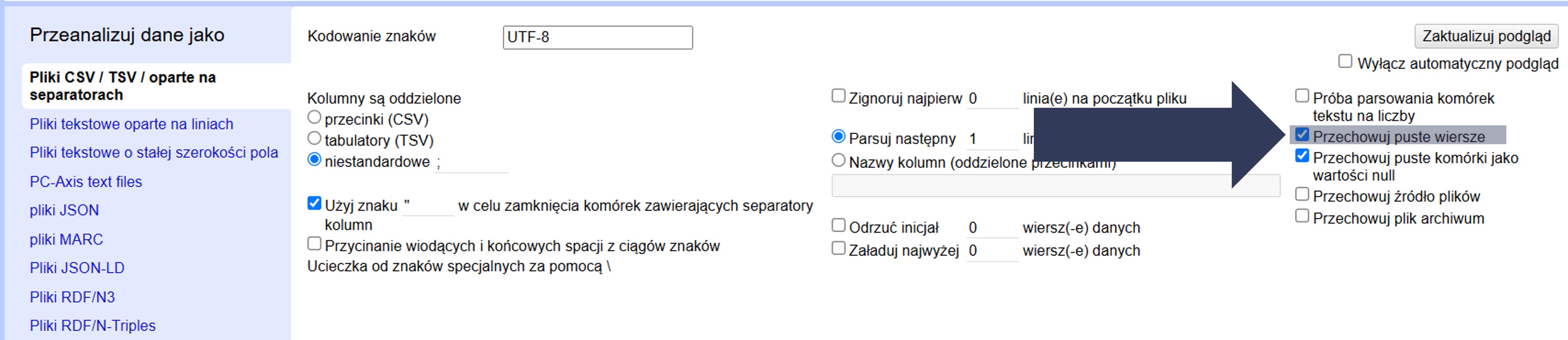
- Sprawdź w podglądzie danych (górna część okna), czy puste wiersze są widoczne w strukturze projektu.
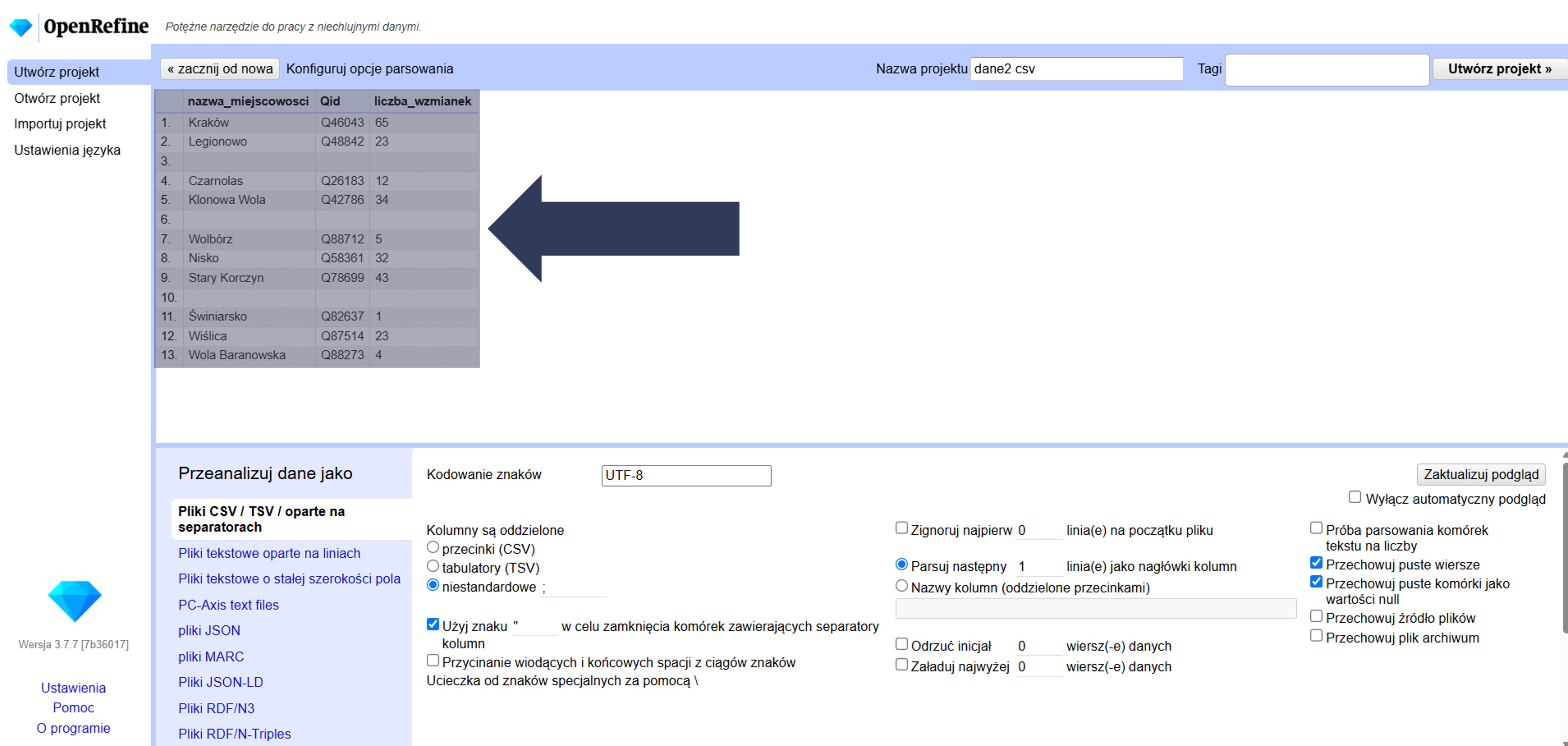
Puste wiersze zostaną zachowane w projekcie i będą widoczne między rekordami.
Uwaga: odznaczenie tej opcji spowoduje usunięcie pustych wierszy podczas importu. Zachowywanie pustych wierszy bywa pomocne przy zachowaniu układu sekcji, ale może utrudniać operacje liczenia/filtrowania.
8.2.4.2.12 Interpretacja pustych pól
Puste pola w danych mogą być zapisane jako brak wartości (null) albo jako pusty tekst („”). To ustawienie decyduje, jak OpenRefine zapisze takie komórki.
Aby przechowywać puste komórki jako wartości null:
- W sekcji Opcje importu zaznacz pole Przechowuj puste komórki jako wartości null.
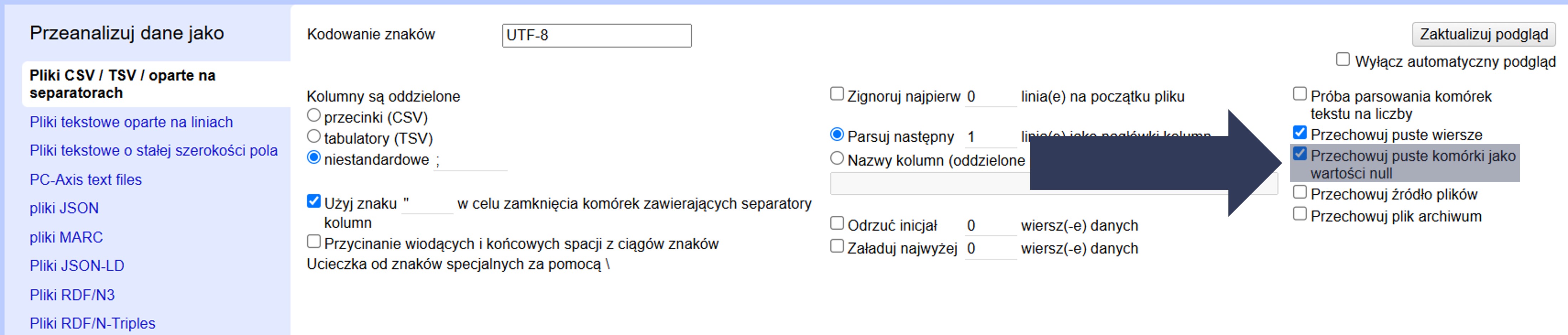
- Sprawdź w podglądzie danych, czy puste pola są oznaczone jako null, a nie jako pusty tekst.
Puste komórki zostaną zapisane jako null (brak wartości), co wpływa m.in. na fasety, filtrowanie i operacje typu „usuń wiersze z brakami”.
Uwaga: odznaczenie tej opcji spowoduje zapis pustych pól jako pustych ciągów („”), które są traktowane jak tekst (mogą pojawiać się w fasetach jako osobna wartość).
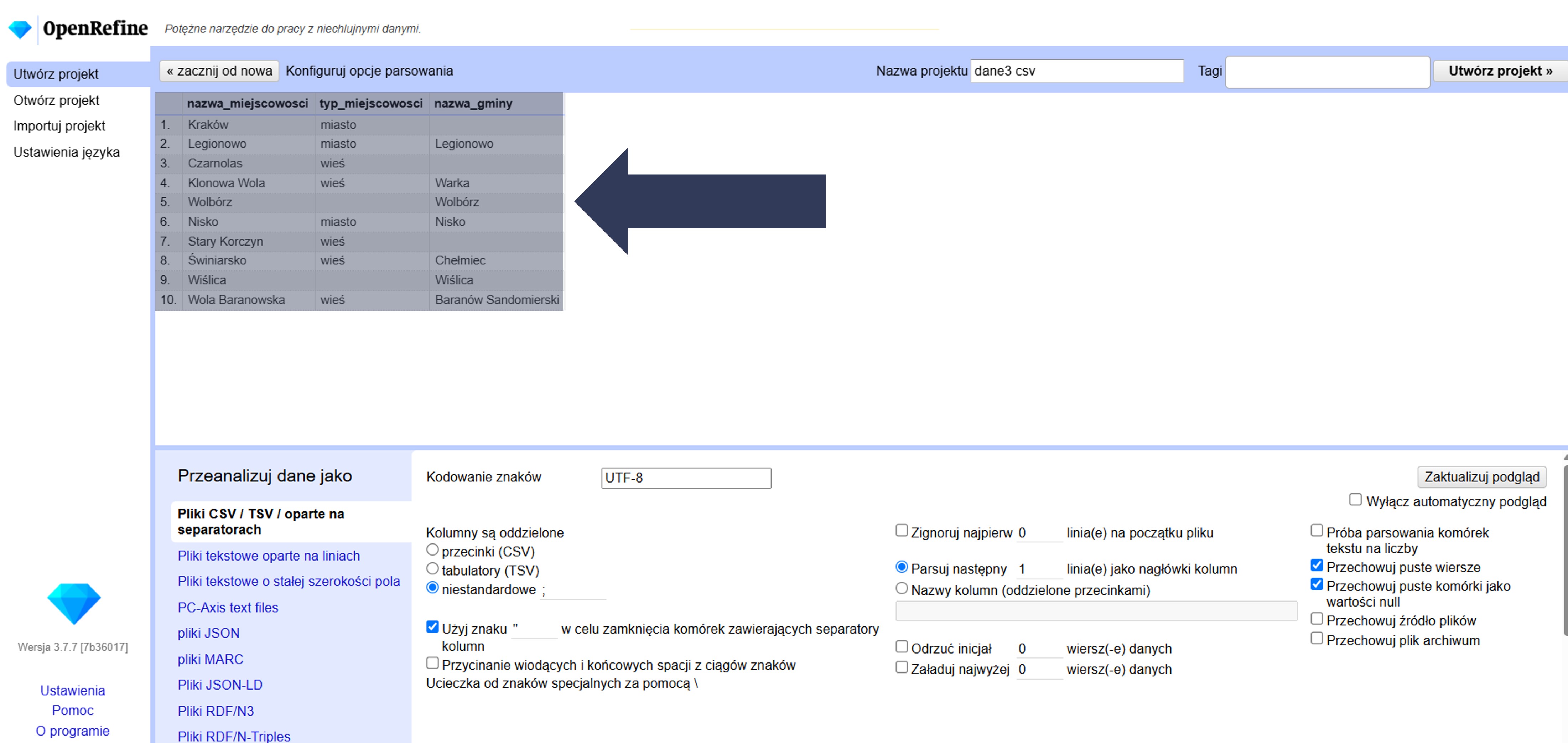
8.2.4.2.13 Przechowywanie pliku źródłowego w katalogu projektu
Domyślnie OpenRefine tworzy projekt na podstawie danych wejściowych. Możesz dodatkowo zachować oryginalny plik źródłowy w katalogu projektu (dla odtwarzalności i audytu).
Aby zachować oryginalny plik źródłowy w katalogu projektu:
- W sekcji Opcje importu zaznacz pole Przechowuj źródło plików.
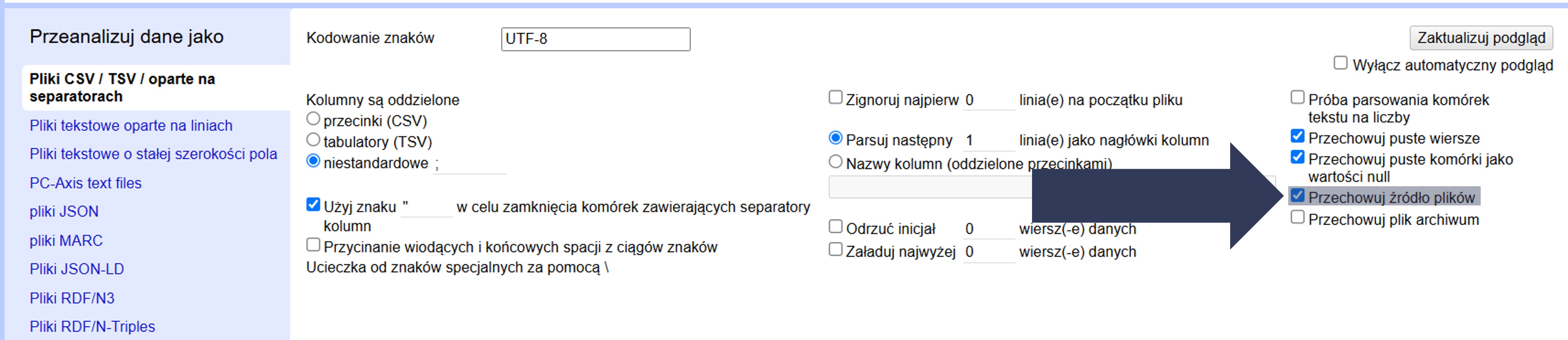
- Po imporcie sprawdź w katalogu projektu, czy plik źródłowy został zapisany wraz z danymi projektu.
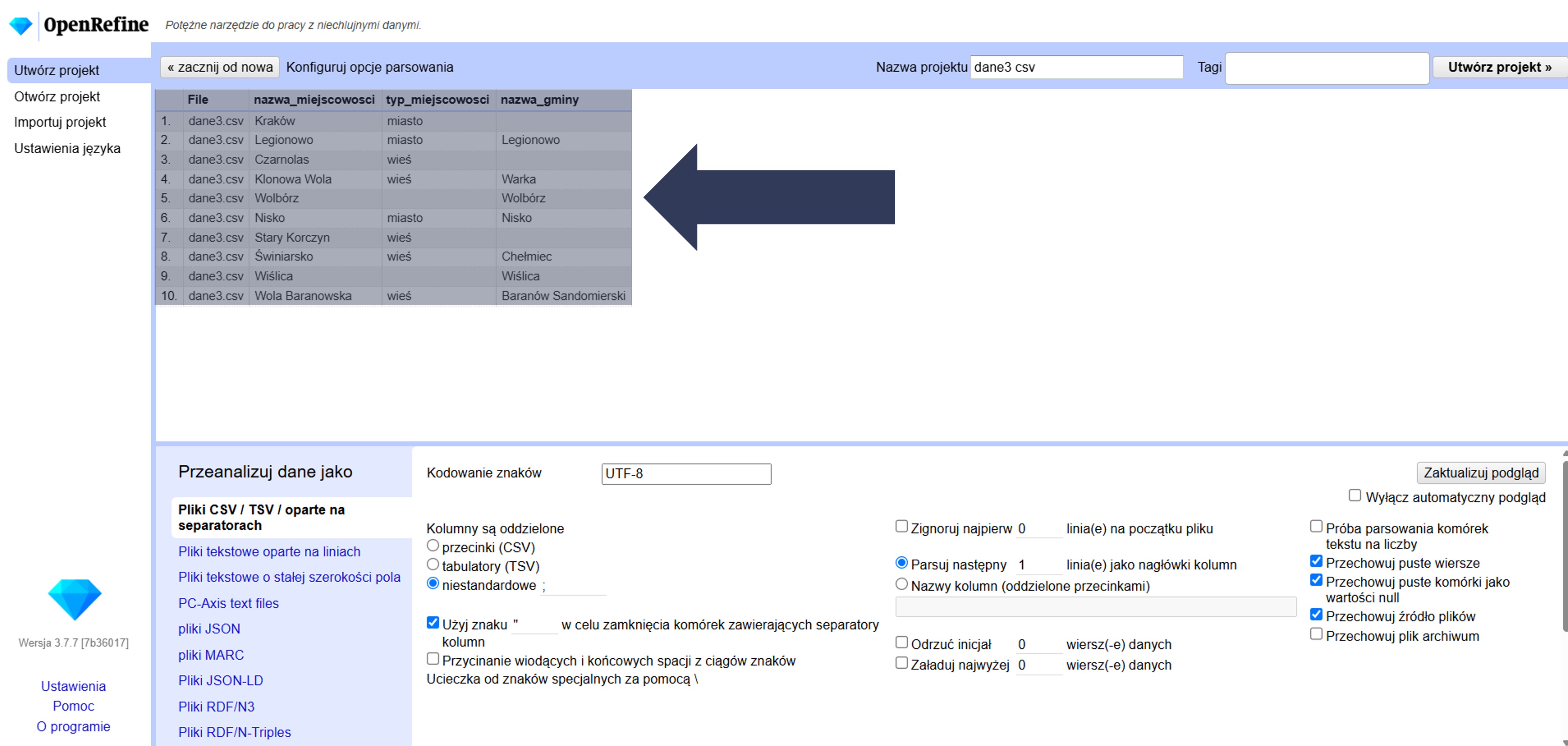
Oryginalny plik zostanie dołączony do projektu, co ułatwia weryfikację i ponowne przetwarzanie danych.
Uwaga: włączenie tej opcji zwiększa zużycie miejsca na dysku (kopiowany jest pełny plik źródłowy).
8.2.4.2.14 Przechowywanie archiwum źródłowego w projekcie
Czasem dane są wgrywane z archiwum (np. ZIP). OpenRefine może zachować cały plik archiwum w katalogu projektu, aby w każdej chwili móc wrócić do oryginalnego pakietu danych.
Aby przechowywać całe archiwum w projekcie:
- W sekcji Opcje importu zaznacz pole Przechowuj plik archiwum.
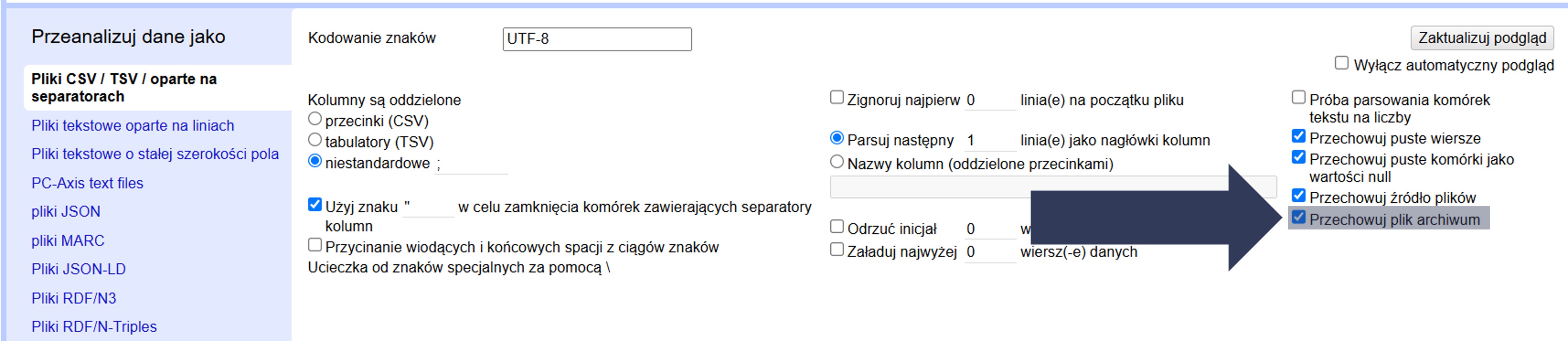
- Po imporcie sprawdź w podglądzie oraz w katalogu projektu, czy archiwum zostało dołączone do projektu.
Oryginalny plik ZIP (lub inne archiwum) zostanie zachowany wraz z projektem — ułatwia to audyt i odtwarzalność procesu.
Uwaga: włączenie tej opcji może zwiększyć rozmiar projektu (przechowywany jest pełny plik archiwum, oprócz wyodrębnionych danych).
Kolory o wysokim kontraście
Rozmiar czcionki
Czcionka